LuantiはマイクラEEが今あるブロックを使って世界を作り上げるボクセルゲームであるとすると、LuantiはLuaを使ってnode(ブロック)の定義もできるしロジックの記述もできます
で、簡単なロジックを作ってみた
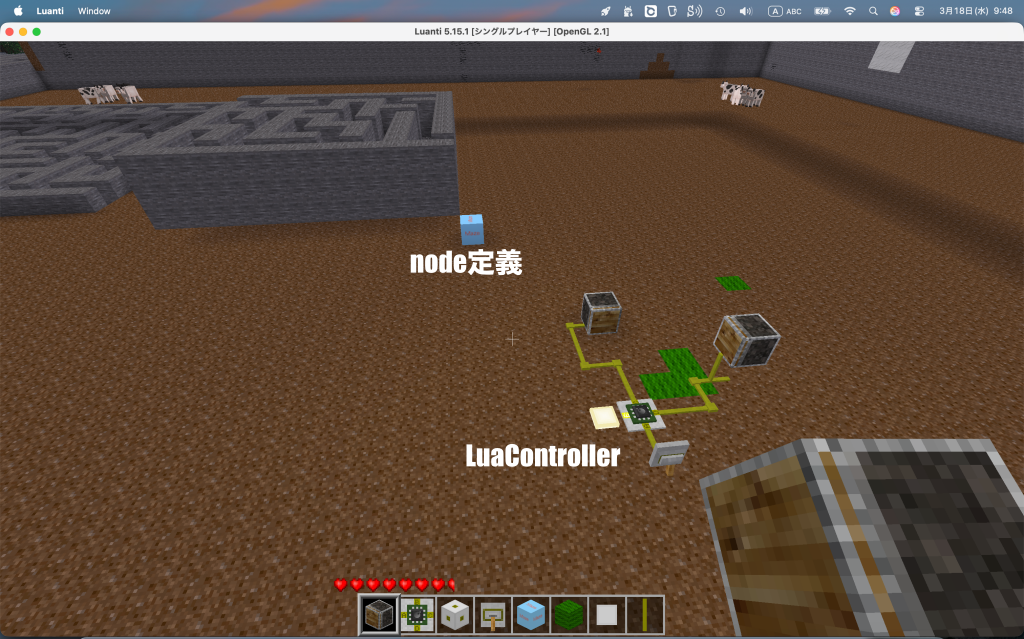
LuaControllerは何をやっているかというと、最初にport Bのランプを点灯させ、レバーの状態を待ち受けてonになれば、乱数でport C or Dのピストンを押し出し、1秒経過したらピストンを戻すという処理になってます
LuaControllerのLuaコードは、
port.b = true
-- Aポートからの入力を監視
if event.type == "on" and event.pin.name == "A" then
-- 1か2の乱数を生成
local choice = math.random(1, 2)
if choice == 1 then
-- CポートをONにする
port.c = true
-- 0.5秒後にOFFにする(ピストンの動作時間を確保)
interrupt(1.0, "reset")
else
-- DポートをONにする
port.d = true
interrupt(1.0, "reset")
end
end
-- 指定した時間が経過した後にポートをすべてOFFにする
if event.type == "interrupt" and event.iid == "reset" then
port.c = false
port.d = false
end
wordpressの編集でLua言語とか選択できないからPythonになってますが、特徴的なのはCPUを占有できないから(ゲーム全体が止まる)、interrupt()はイベントリスナーでタイムアウトを待っていること、この例に限らずイベントリスナーあるいはcallbackを使うのは標準になってます
次にnode定義ですが、定義の作法は、他のmodsも全て共通ですが、modsディレクトリ配下に新たなmod(ここではmaze)を定義し、mod.confファイルとluaのロジックファイルを配置します
またnodeの表面の画像表示にはstr_maze.png(32*32 dots)を用意しています、六面個別に指定もできますが、一個だけ記載すると六面全部に適用されます
・ディレクトリ構成
mods/
maze/
mod.conf
init.lua
textures/
str_maze.png
・mod.conf
name = maze
description = stick-falling maze generator
ここでは何をやっているかというと、棒倒し法での迷路作成を実行しています
nodeを右クリックすると対象のエリアをクリアして、新たにnodeの石を配置して出入り口を設けるという処理
math.randomseed(minetest.get_us_time())
local function generate_maze(size)
local maze = {}
-- 1. 初期化:すべてを「通路(0)」にする
for x=1,size do
maze[x] = {}
for z=1,size do maze[x][z] = 0 end
end
-- 2. 外壁と「格子状の柱」を配置
-- 柱は 3, 5, 7... (size-2) の奇数地点に配置するのが棒倒し法の正解です
for x=1,size do
for z=1,size do
if x==1 or z==1 or x==size or z==size then
maze[x][z] = 1 -- 外壁
elseif x%2==1 and z%2==1 then
maze[x][z] = 1 -- 柱
end
end
end
-- 3. 棒倒し
-- 柱(3, 5, 7...)から棒を倒す
for z=3, size-2, 2 do
for x=3, size-2, 2 do
local dirs = {{0,1}, {1,0}, {-1,0}} -- 下、右、左
if z == 3 then table.insert(dirs, {0,-1}) end -- 最初の行だけ上も許可
-- シャッフル
for i = #dirs, 2, -1 do
local j = math.random(i)
dirs[i], dirs[j] = dirs[j], dirs[i]
end
-- 棒を倒す
for _, d in ipairs(dirs) do
local tx, tz = x + d[1], z + d[2]
-- 出入り口 (2,1) と (size-1,size) に隣接する場所は倒さない
local is_near_entrance = (tx == 2 and tz == 1) or (tx == 2 and tz == 2)
local is_near_exit = (tx == size-1 and tz == size) or (tx == size-1 and tz == size-1)
if maze[tx][tz] == 0 and not is_near_entrance and not is_near_exit then
maze[tx][tz] = 1
break
end
end
end
end
-- 4. 出入り口の最終的な穴あけ
maze[2][1] = 0
maze[size-1][size] = 0
return maze
end
-- 配置関数(高さ3マスの壁を生成)
local function build_maze(pos, size)
local m = generate_maze(size)
for dx=0, size+1 do
for dz=0, size+1 do
for dy=0, 4 do
minetest.set_node({x=pos.x+dx, y=pos.y+dy, z=pos.z+dz}, {name="air"})
end
end
end
for x=1, size do
for z=1, size do
local p = {x=pos.x+x, y=pos.y, z=pos.z+z}
if m[x][z] == 1 then
for y_off=0, 2 do
minetest.set_node({x=p.x, y=p.y+y_off, z=p.z}, {name="default:stone"})
end
else
minetest.set_node(p, {name="default:cobble"})
for y_off=0, 2 do
minetest.set_node({x=p.x, y=p.y+y_off+1, z=p.z}, {name="air"})
end
end
end
end
end
minetest.register_node("maze:maze_generator", {
description = "迷路生成ノード",
tiles = {"str_maze.png"},
groups = {cracky = 1},
on_rightclick = function(pos, node, clicker)
local start_pos = {x = pos.x, y = pos.y + 1, z = pos.z}
build_maze(start_pos, 13)
end,
})
最後のminetest.register_node()関数がnodeの登録処理で、右クリックで起動するようになっています
先にも述べた通り、全てのmodsはディレクトリ構成は全て共通なので、例えばmodsライブラリからダウンロードしてきたmodsも改造は自由にできます(例えば見え方をtexture入れ替えて変えるとか)
という感じで、自分だけのワールドの作り上げることができるのがLuantiの最大の特徴でしょう
admin