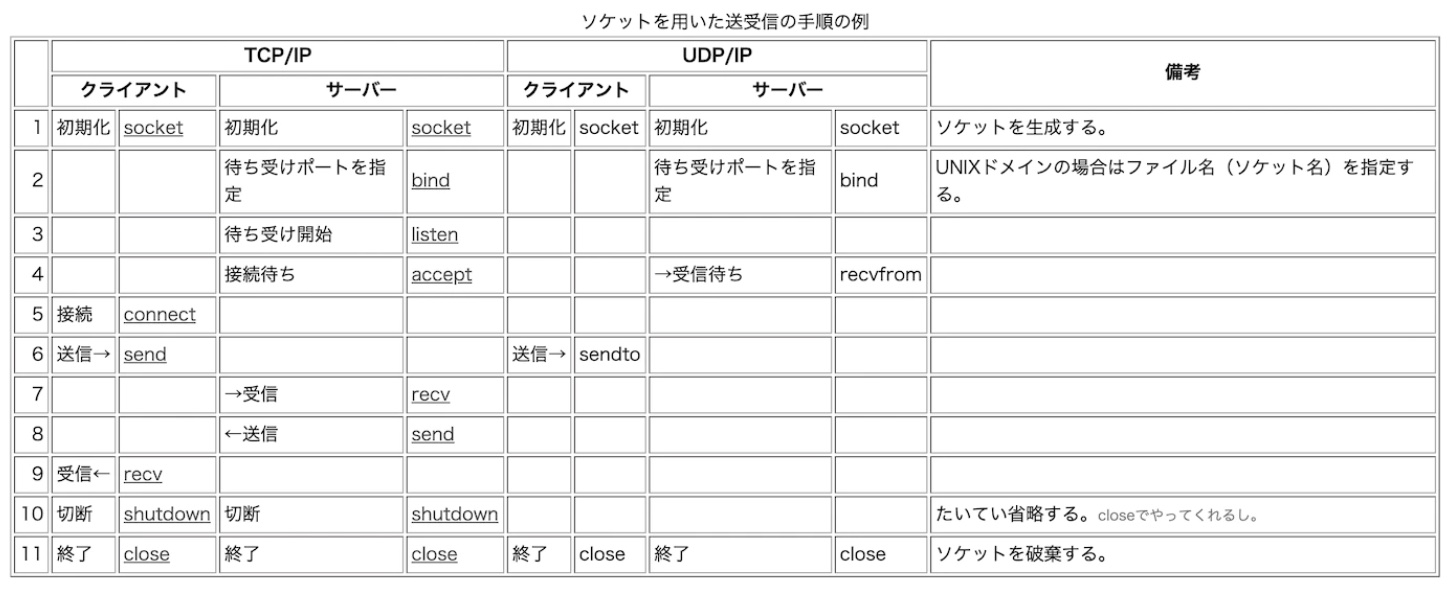
マルチスレッドは多くのアプリケーション、わかりやすいのはブラウザあたり、で普通に使われてますが、多重度を上げても必ずしも性能が向上するわけではありません。それはリソースの排他制御などでオーバーヘッドが発生するから。
で、素数計算プログラムでマルチスレッドの効果を検証してみた。
<ソースコード>
スレッド制御はstd::threadクラスを使います。
https://cpprefjp.github.io/reference/thread/thread.html
スレッドプログラミングで問題になる共通リソース、この場合には計算対象の整数(cal_int)と計算結果の格納(vec{})を排他制御(mutex)で、壊れないように制御します、理屈はセマフォーと同じです。
同じ処理の多重化ならば、特定の関数をスレッド化する訳なので、元のコードは一個で構いません。
スレッド数の可変は対象部分(std::thread th_x(ThreadA); とth_x.join();)をコメントアウトで対応。
算出結果のvectorはスレッドの出力タイミングでソートされた結果にはならないから、処理完了後にソートを実行。
スレッド処理の記述は、
https://qiita.com/nsnonsugar/items/be8a066c6627ab5b052a
を参考。
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
#include <cmath>
std::mutex mtx_; // mutex for exclusive control
std::vector vec{}; // prime numbers array
int cal_int = 1; // calc target integer
int max_int = 10000000; // calc target max number
void add_prime(int i)
{
std::lock_guard lock(mtx_);
vec.push_back(i);
}
int get_int()
{
std::lock_guard lock(mtx_);
++cal_int;
return cal_int;
}
void ThreadA()
{
while (true)
{
bool flag = false;
int i = get_int();
if (i > max_int)
{
break;
}
int sqt = sqrt(i);
for (int j = 2; j <= sqt; ++j){
if (i%j == 0){
flag = true;
break;
}
}
if (flag != true){
add_prime(i);
}
}
}
int main()
{
std::chrono::system_clock::time_point start, end;
start = std::chrono::system_clock::now();
std::cout << std::endl;
std::cout << "Hardware concurrency = " << std::thread::hardware_concurrency() << std::endl;
std::thread th_a(ThreadA);
std::thread th_b(ThreadA);
std::thread th_c(ThreadA);
std::thread th_d(ThreadA);
th_a.join();
th_b.join();
th_c.join();
th_d.join();
std::cout << std::endl;
end = std::chrono::system_clock::now();
double elapsed = std::chrono::duration_cast(end-start).count();
std::cout << "elapsed time : " << elapsed << " ms" << std::endl;
std::sort(vec.begin(), vec.end() );
for (auto itr = (vec.end() - 5); itr != vec.end(); ++itr){
std::cout << *itr << std::endl;
}
return 0;
}
<実行結果>
対象が百万までではスレッド数が2以上による実行時間の差はほとんどない。スレッドの実行時間よりもオーバーヘッドの方が支配的だからだろう。
一方、千万までの計算ではスレッド処理の比重が増加して、スレッド数を増やせば実行時間は速くなるから、スレッド処理が支配的になるせいでしょう。
Hardware concurrency = 12
—100000まで計算—
1 thread
elapsed time : 223 ms
999953
999959
999961
999979
999983
2 threads
elapsed time : 177 ms
999953
999959
999961
999979
999983
3 threads
elapsed time : 184 ms
999953
999959
999961
999979
999983
4 threads
elapsed time : 194 ms
999953
999959
999961
999979
999983
—10000000まで—
1 thread
elapsed time : 4519 ms
9999937
9999943
9999971
9999973
9999991
2 threads
elapsed time : 2646 ms
9999937
9999943
9999971
9999973
9999991
3 threads
elapsed time : 2103 ms
9999937
9999943
9999971
9999973
9999991
4 threads
elapsed time : 1829 ms
9999937
9999943
9999971
9999973
9999991
という結果が言わんとすることは、各スレッドの処理が重ければCPUのマルチコアが有効に働く、しかし処理が軽いとオーバーヘッドによりほとんど実行時間には影響しない。もちろんマルチスレッドの目的は処理の分散・並行処理による高速化以外に各スレッド処理のリアルタイム性の側面もあるのだから、一概には言えないわけだけれども、いずれにしろ適用アプリケーションを事前に考慮した上での実装が必要という当たり前の結論です。
admin