
どの言語にも存在すると思いますがrecursive call(再帰呼び出し)、よく例として挙げられるのがnの階乗です。
recur()が再起呼び出しを使う方法でfact()は通常の繰り返し処理です。これだけ見たらなぜ再起処理必要なのというところでしょうが、例えばbinary tree(二分木)ではrecursive callが必須でこれ以外の方法ではうまく記述できないはずです。
package main
import (
"fmt"
)
func main(){
fmt.Println(recur(10))
fmt.Println(fact(10))
}
// recursive call
func recur(n int) int{
if n == 2{
return 2
}
return n*recur(n -1)
}
// conventional method
func fact(n int) int{
m := 1
nf := n
for i := 1; i <= n; i++{
m *= nf
nf--
}
return m
}
以下はweb上に挙げられてるソースにノードの遷移がわかるようにPrint文を埋め込んだものです。よく見るとinsert()もprintNode()も再帰処理を使って同じような構造になっているのが理解できると思います。さらにdelete()を追加してもそうなります。
/*
https://selfnote.work/20210930/programming/golang-binary-tree-2/
*/
package main
import (
"fmt"
)
type Tree struct {
node *Node
}
type Node struct {
value int
left *Node
right *Node
}
func (t *Tree) insert(value int) *Tree {
if t.node == nil {
t.node = &Node{value: value} // used only at the first node
} else {
t.node.insert(value)
}
return t
}
func (n *Node) insert(value int) {
if n.value >= value {
if n.left == nil {
n.left = &Node{value: value}
fmt.Println("value_add_l", value)
} else {
fmt.Println("skip_l", value, n.left.value)
n.left.insert(value)
}
} else {
if n.right == nil {
n.right = &Node{value: value}
fmt.Println("value_add_r", value)
} else {
fmt.Println("skip_r", value, n.right.value)
n.right.insert(value)
}
}
}
var i = 0
func printNode(n *Node) {
if n == nil {
i += 1
fmt.Print("nil;")
return
}
fmt.Println("value", n.value)
printNode(n.left)
fmt.Println("l",i, "node", n.value)
printNode(n.right)
fmt.Println("r",i, "node", n.value)
}
func main() {
t := &Tree{}
t.insert(2).
insert(7).
insert(5).
insert(6).
insert(1).
insert(11).
insert(9).
insert(4).
insert(20).
insert(10)
fmt.Println("-----------------------")
printNode(t.node)
}以下に実行結果から手書きでprintNode()の遷移を書いてみましたが、このように動作してます。
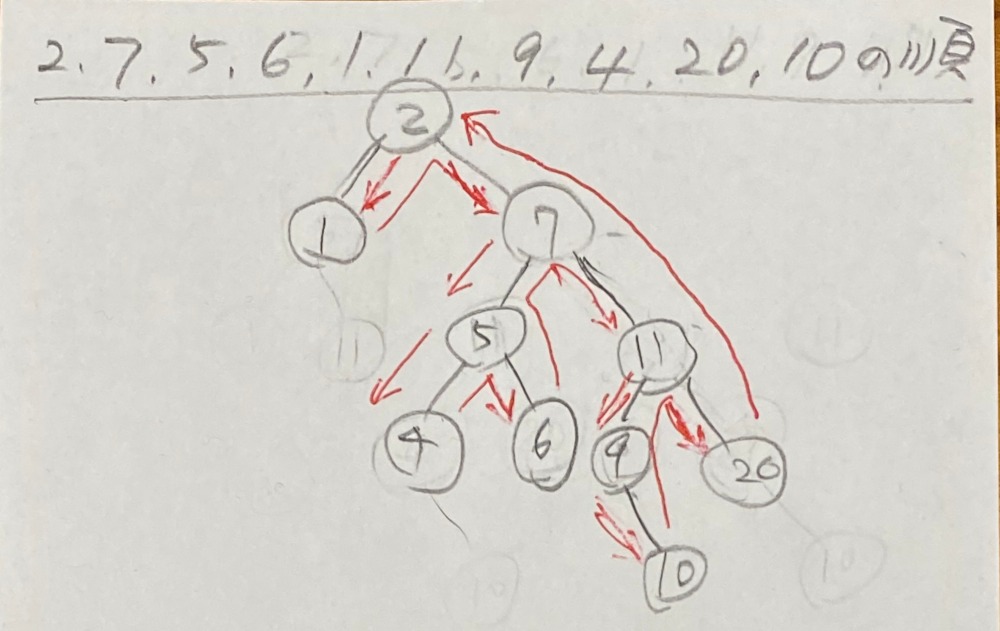
で、binary treeってどこで使われるの?ですがエンドのアプリで記述するよりもDBの内部処理などでは当たり前に使われているようです。insert(), delete(), search()ってDBでは普通に使われて、なおかつそれらを配列やスライスで表現させるとデータ追加の都度に再度作り直しが発生しますが、binary treeならば追加処理も簡単、さらにはアクセスも平均でn*log(n)で済むだろうから効率的であるとも言えます。
admin