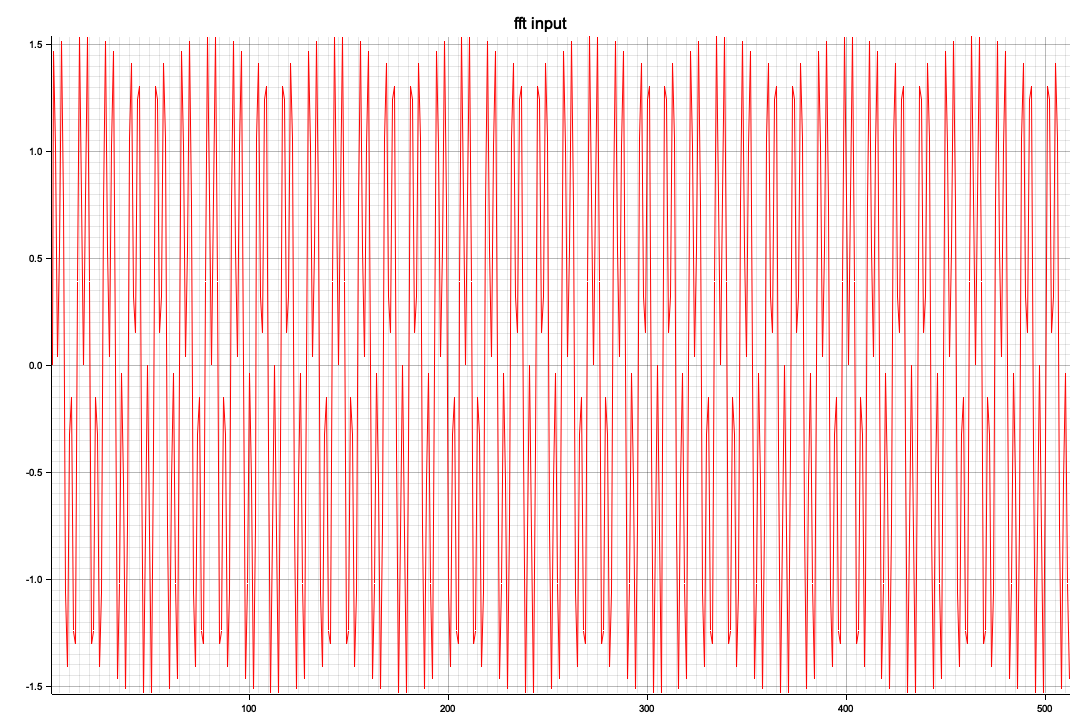
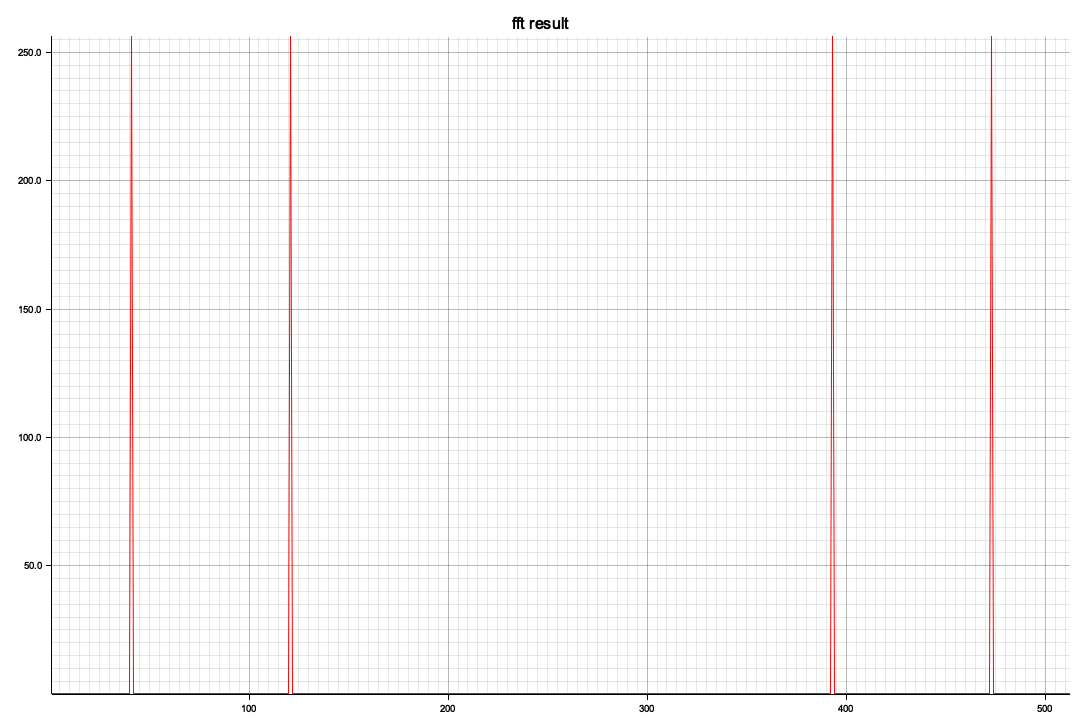
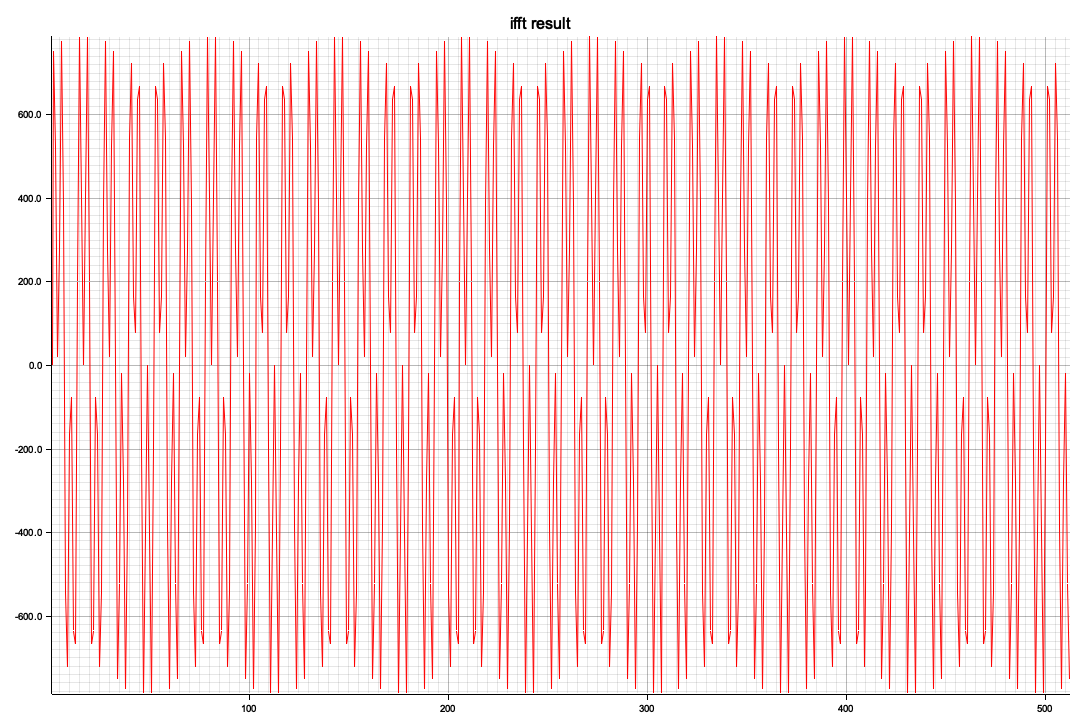
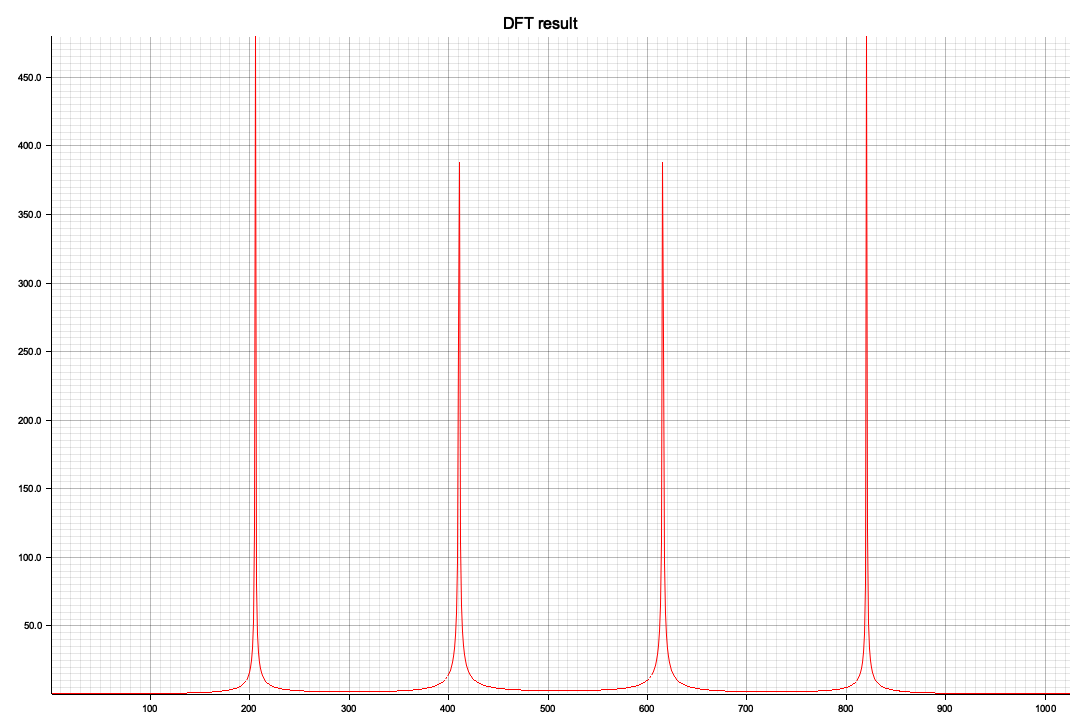
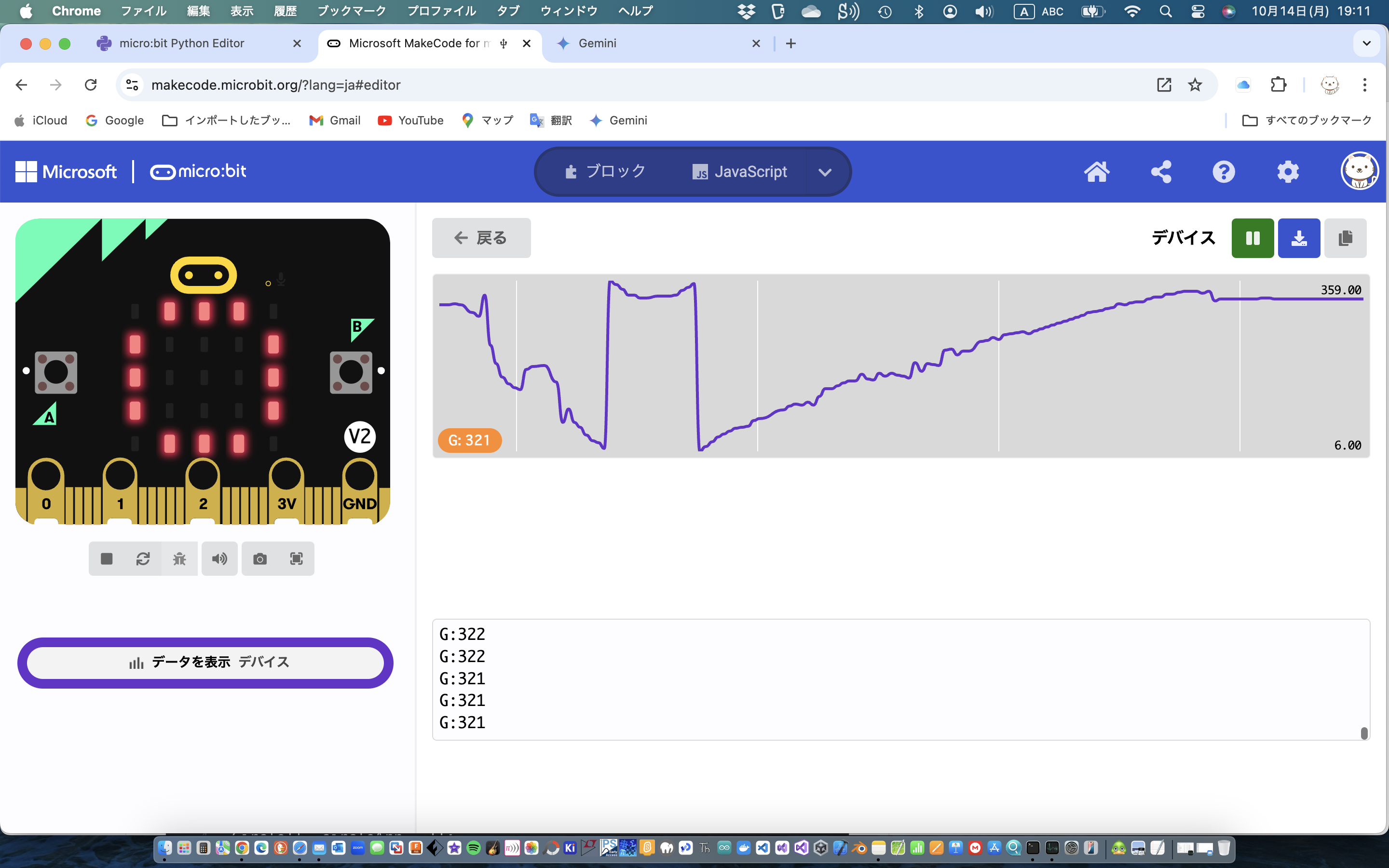
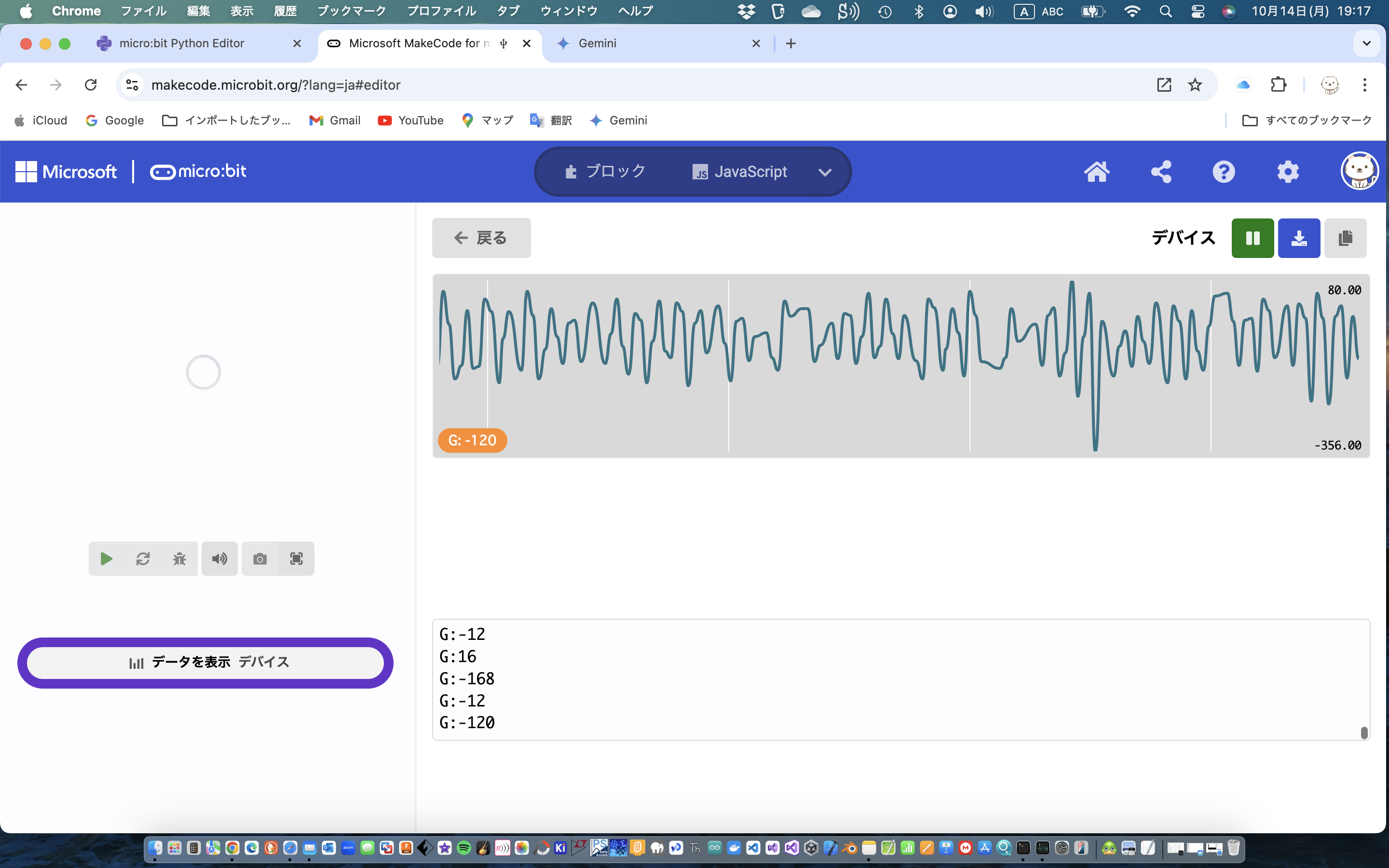
正弦波の合成だけでは実用性はないので、今年の元旦の能登地震の公開されている波形データからスペクトルを求めてみた
公開先はこちらですが、トップにある輪島市のデータを使っています、形式はcsvなのでヘッダー情報除けばPythonやRustで簡単に処理できます
・ヘッダー情報
SITE CODE= 67016輪島市門前町走出 ,37.4962,137.2705,15.86,7.6,45292.67387,8.93,15.21
LAT.= 37.2871,,,,,,,
LON.= 136.7680,,,,,,,
SAMPLING RATE= 100Hz,,,,,,,
UNIT = gal(cm/s/s),,,,,,,
INITIAL TIME = 2024 01 01 16 10 10,,,,,,,
NS,EW,UD,,,,,
気象庁|強震観測データ|2024/1/1 石川県能登地方の地震
Pythonで全時間領域を対象にしてみたもの(画像はUD軸)
リンク先にある波形と比較するとほぼ類似の形状になってます
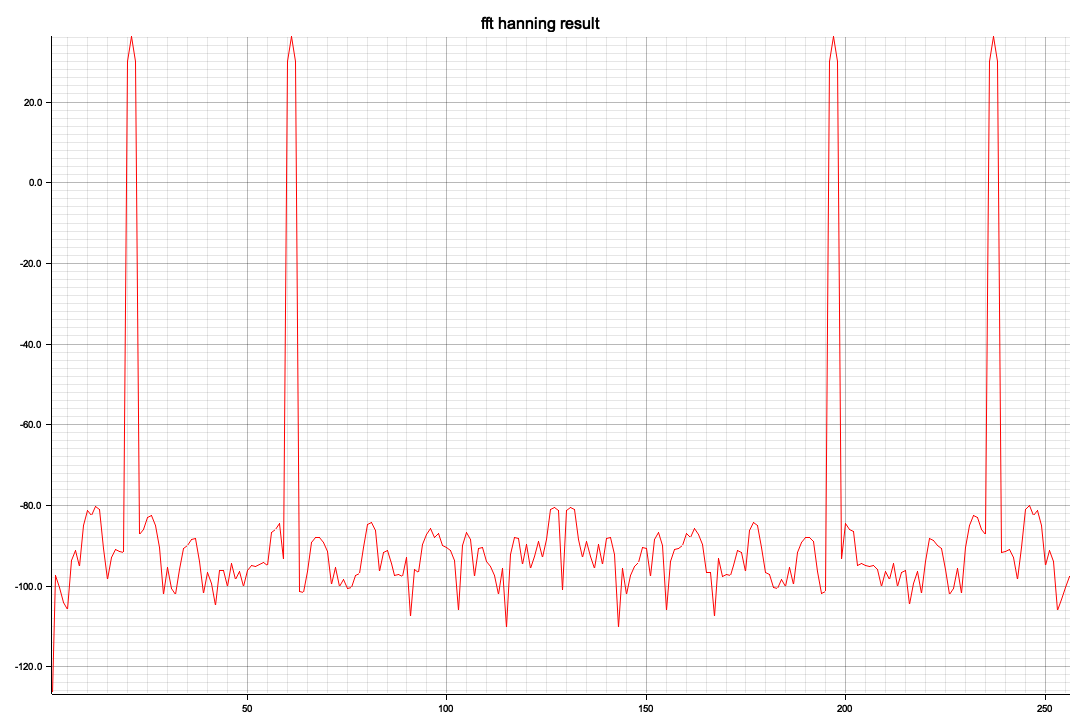
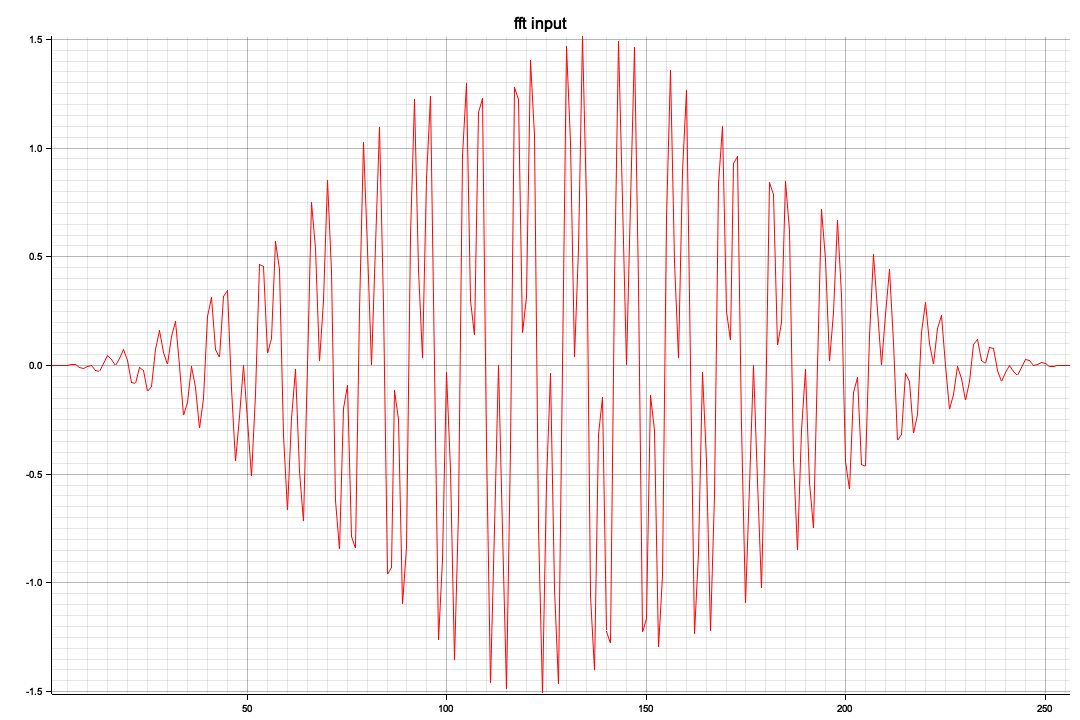
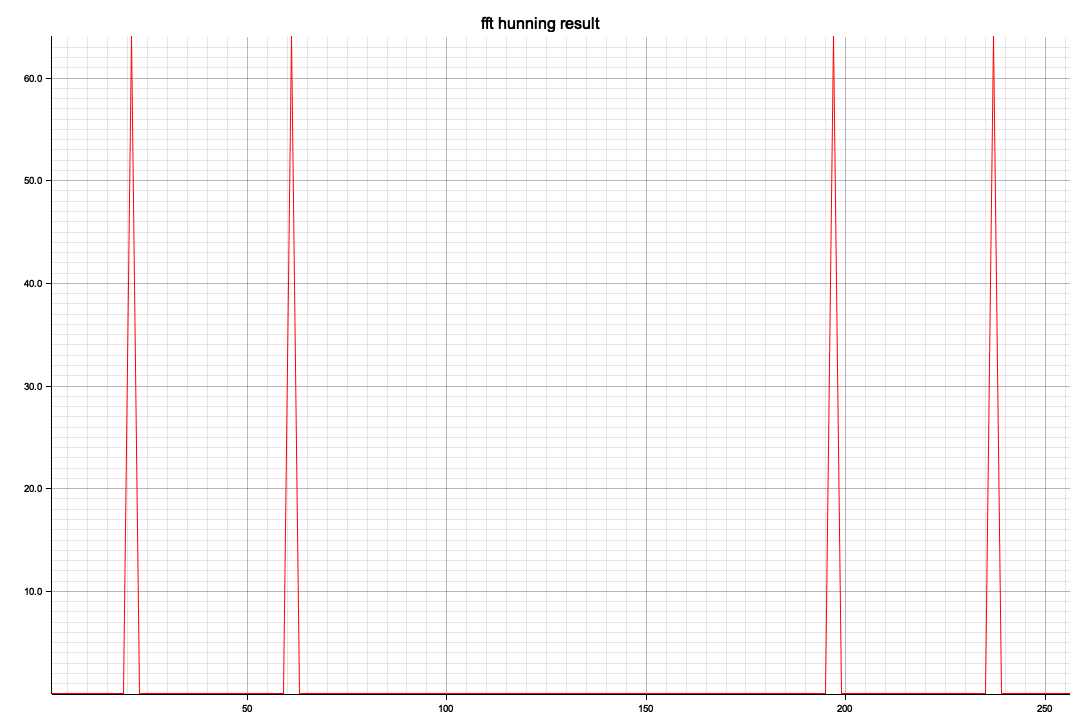
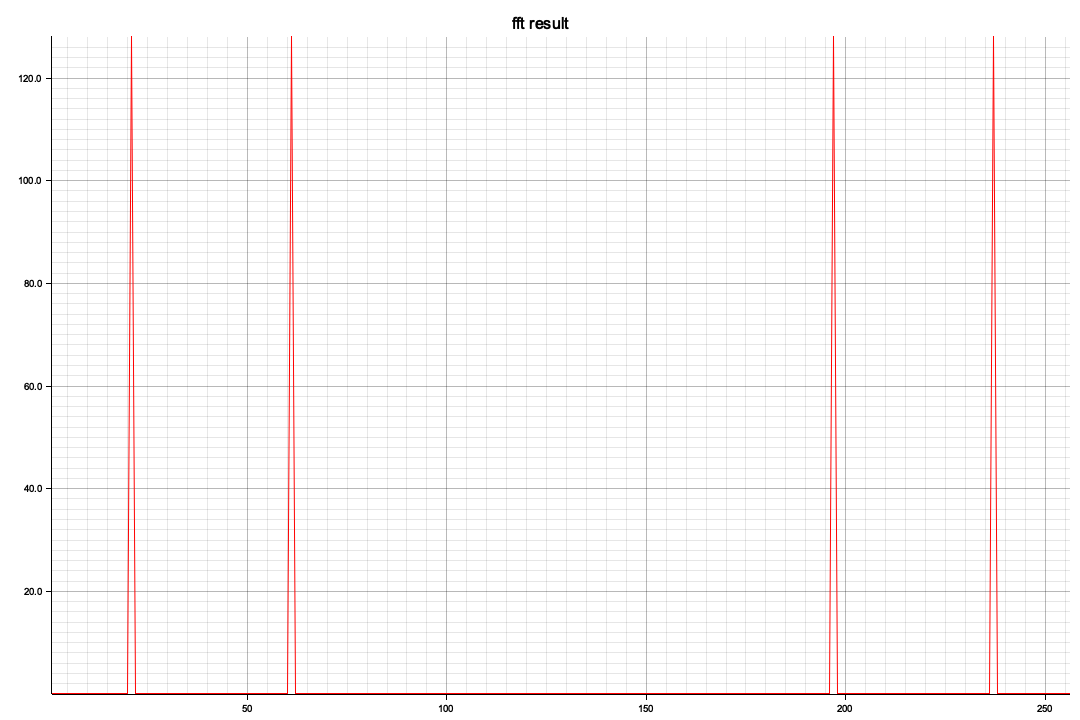
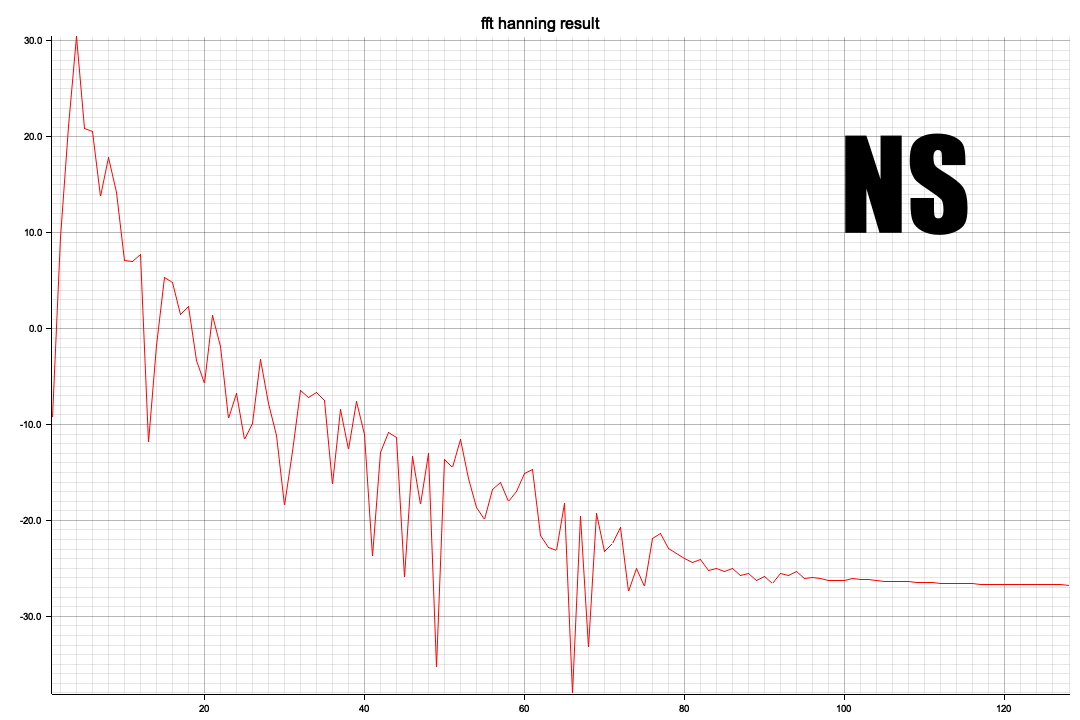
以下はRustで部分切り出し(全体で100サンプル/secで120,000フレーム、つまり120秒分のデータがありますが一番のピークの3,000~4012部分の切り出し)を、窓処理してFFTしてみたもの
<NS波形>
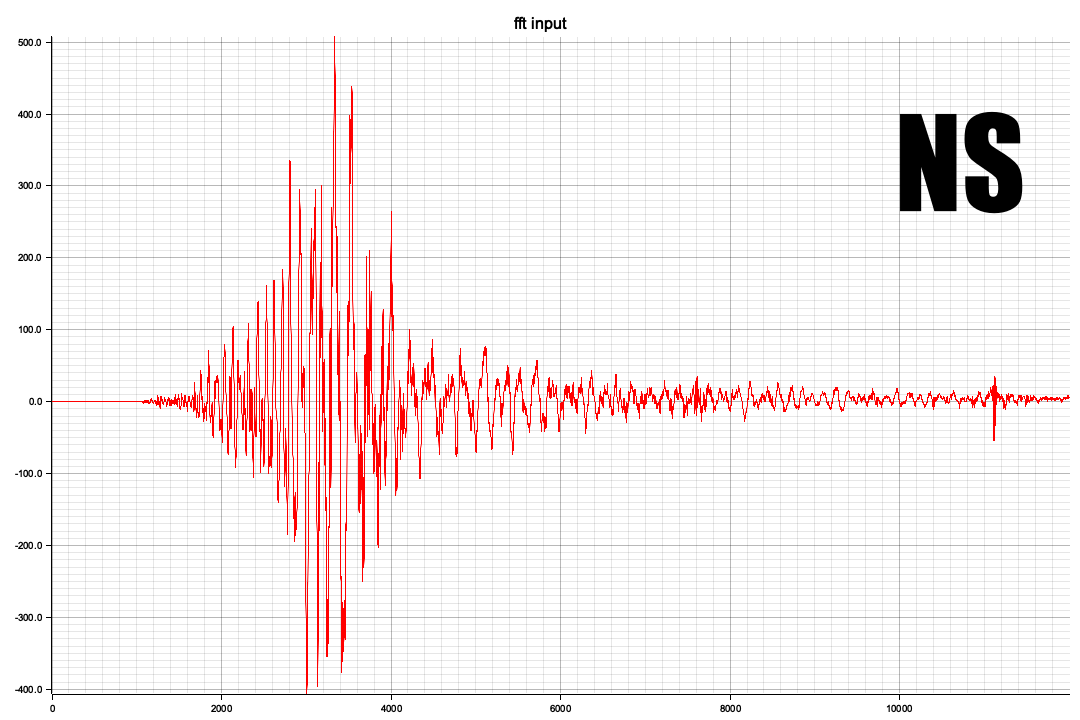
<NSスペクトラム>
以下はEW
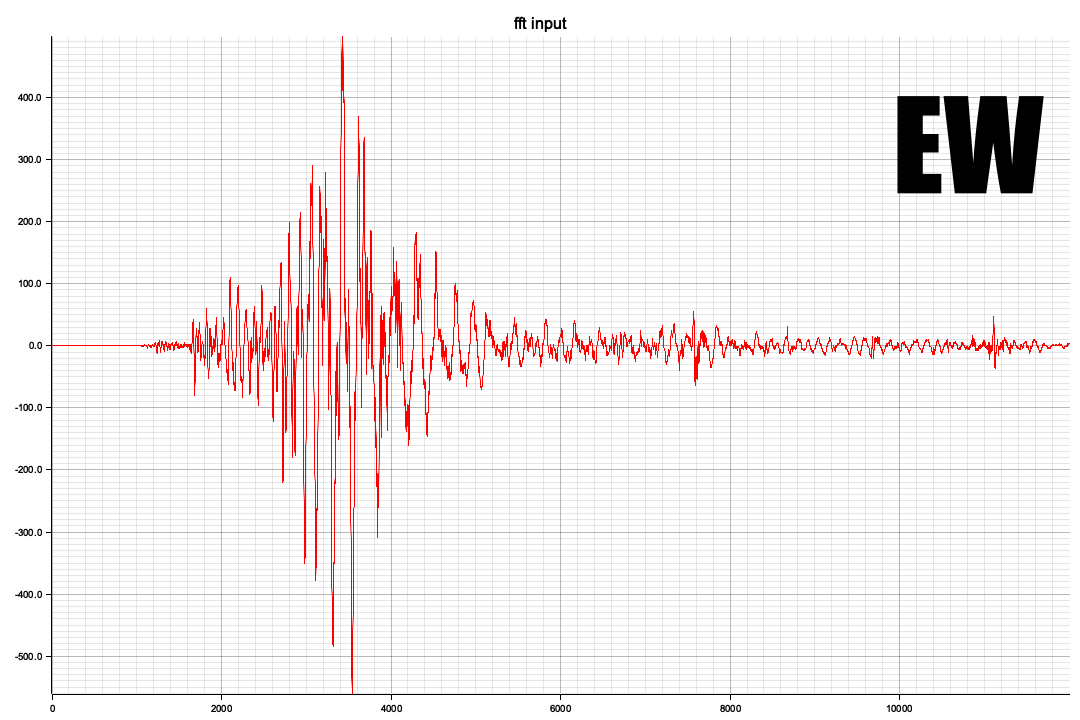
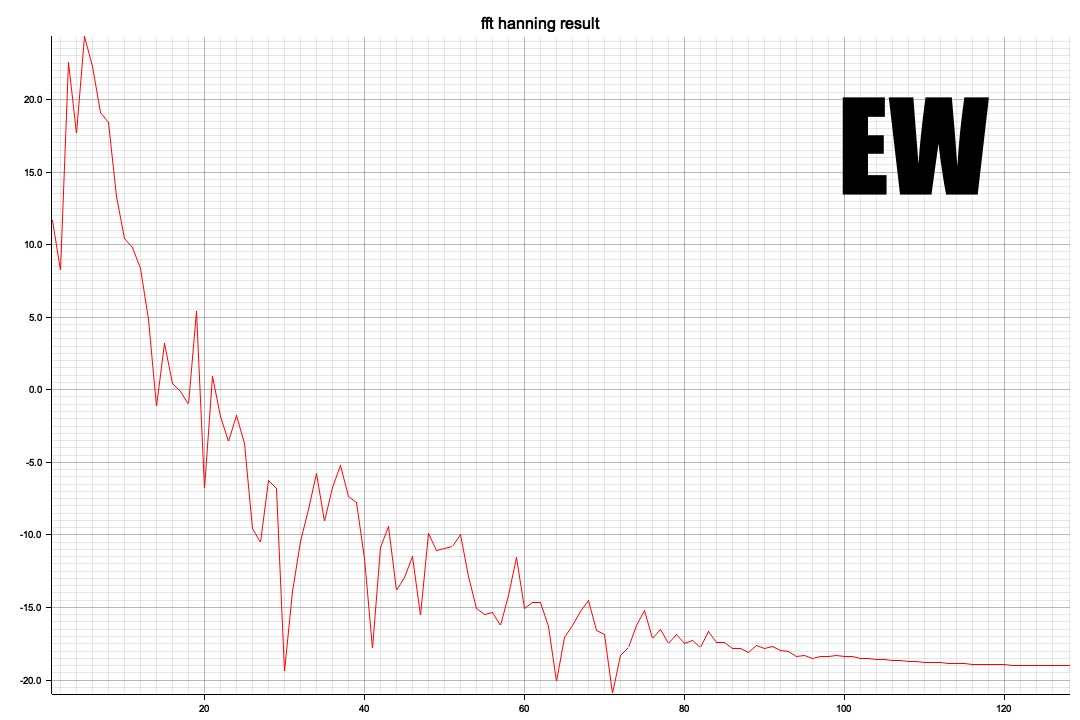
以下はUD
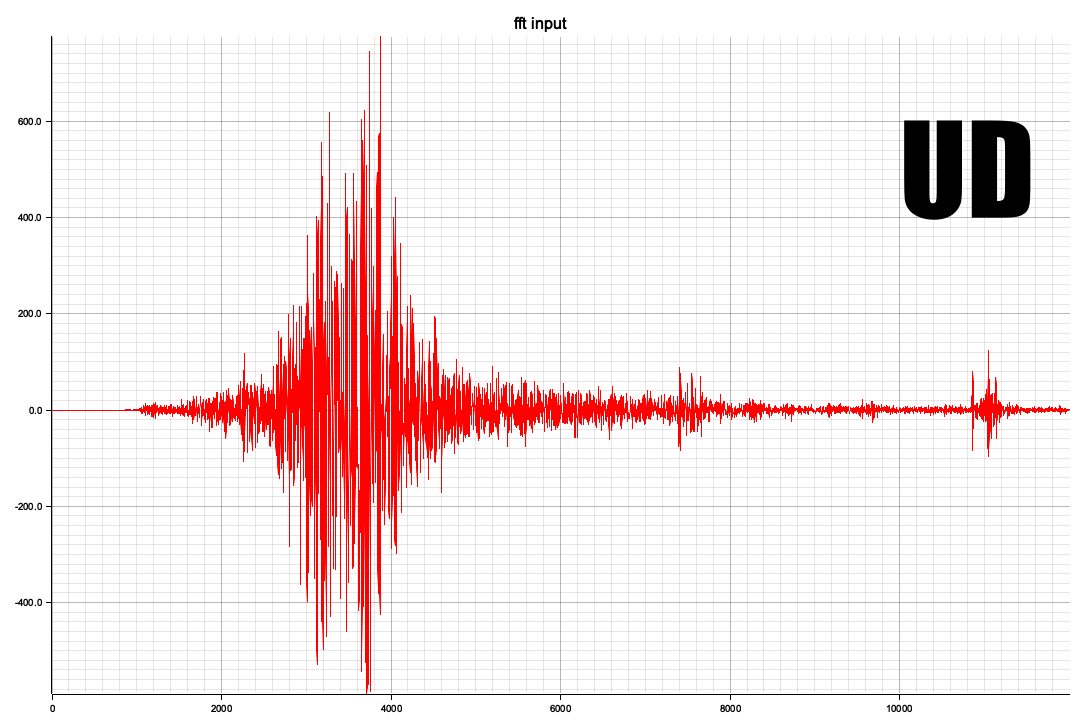
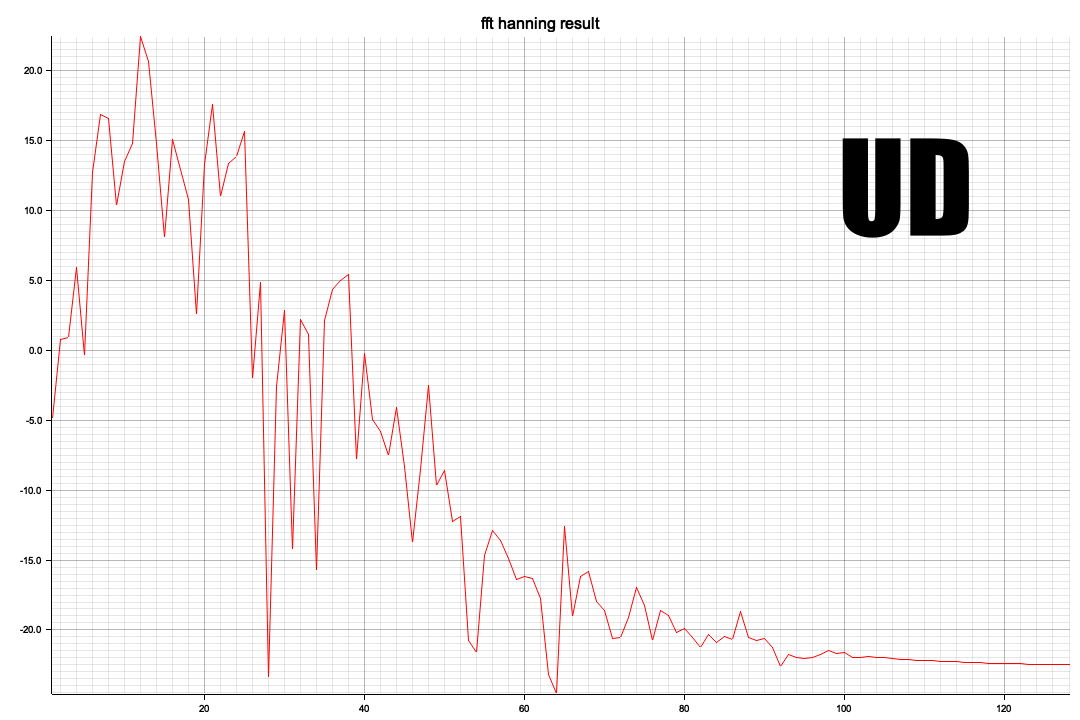
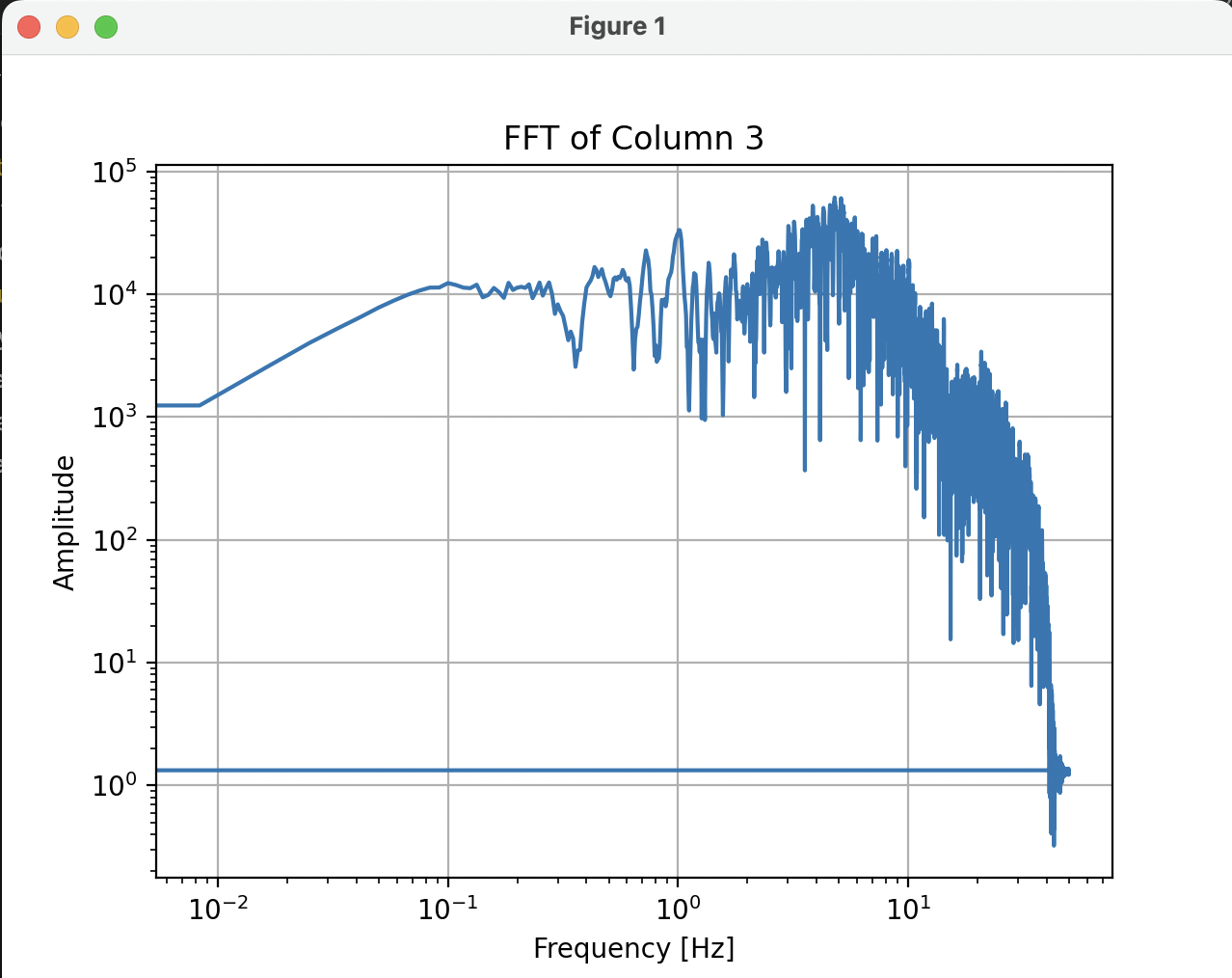
NS/EWに比較すると周波数成分が高い方に出てきます、Pythonの全時間軸ともちろん傾向的には同じようなスペクトルになっています
X軸の20がほぼ10Hzに相当します
以下はPythonのコードになりますが、対話形式でほぼGeminiで作成させたコードがそのまま動きました、きちんと境界条件を与えてやれば人間がコードを書く手間を大幅に省力化できます、コードは読めないとダメですが
import numpy as np
import matplotlib.pyplot as plt
def fft_csv(filename, column_index, sampling_rate):
"""
CSVファイルの特定列データをFFTする関数
Args:
filename: CSVファイルのパス
column_index: FFTしたい列のインデックス (0から始まる)
sampling_rate: サンプリングレート
Returns:
freqs: 周波数
fft_result: FFTの結果
"""
# CSVファイルを読み込む
data = np.loadtxt(filename, delimiter=',', skiprows=1) # ヘッダー行をスキップ
# 指定した列のデータを取得
target_data = data[:, column_index]
# FFTを実行
fft_result = np.fft.fft(target_data)
# 周波数軸を作成
N = len(target_data)
freqs = np.fft.fftfreq(N, 1.0/sampling_rate)
return freqs, fft_result
# 使用例
if __name__ == "__main__":
filename = "noto.csv" # CSVファイル名
column_index = 2 # FFTしたい列 (3列目) 0 :NS/1 :EW/2 :UD
sampling_rate = 100 # サンプリングレート
freqs, fft_result = fft_csv(filename, column_index, sampling_rate)
# 結果をプロット (両対数プロット)
plt.loglog(freqs, np.abs(fft_result))
plt.xlabel("Frequency [Hz]")
plt.ylabel("Amplitude")
plt.title("FFT of Column {}".format(column_index+1))
plt.grid(True)
plt.show()
admin