ラズパイ5ならなんとか処理できそうな、クラウドを使わない、つまりセキュアーな音声認識ソフトでvoskが有力そうだから動かしてみた
元々M1 Macで動かしてみて、small(およそ50MB)と標準の辞書(およそ1.6GB)では明らかに性能差があるから、ラズパイ5でも標準辞書で動かしてみた、懸念はリーズナブルな応答速度で動くかどうか
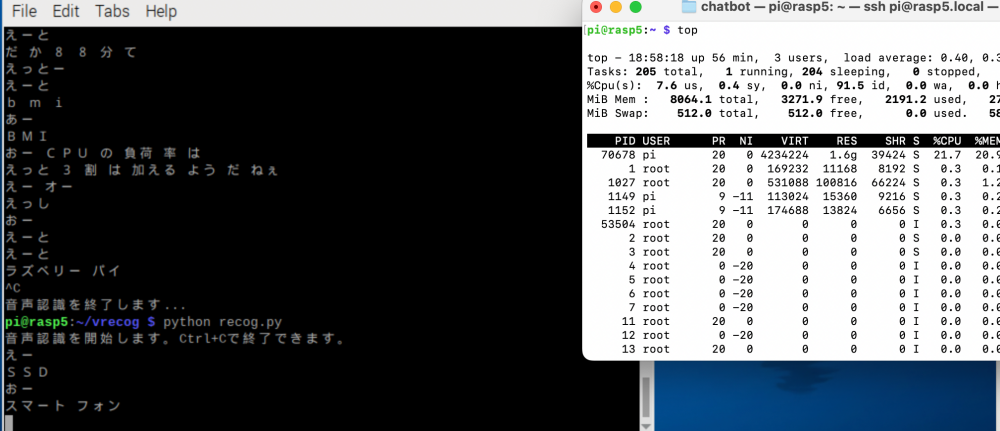
<結果>
まともに動く、cpu負荷率は30%超えるてファンはずっと回るけど使えます
<動作確認コード>
Perplexityで生成したもの、
import vosk
import pyaudio
import json
import numpy as np
import sounddevice as sd
import queue
import threading
import time
class VoskSpeechRecognizer:
def __init__(self, model_path='./vosk-model-ja-0.22'):
# モデルの初期化
vosk.SetLogLevel(-1)
self.model = vosk.Model(model_path)
self.recognizer = vosk.KaldiRecognizer(self.model, 16000)
# キュー設定
self.audio_queue = queue.Queue()
self.stop_event = threading.Event()
# マイク設定
self.sample_rate = 16000
self.channels = 1
# スレッド準備
self.recording_thread = threading.Thread(target=self._record_audio)
self.recognition_thread = threading.Thread(target=self._recognize_audio)
def _record_audio(self):
"""
連続的な音声録音スレッド
"""
with sd.InputStream(
samplerate=self.sample_rate,
channels=self.channels,
dtype='int16',
callback=self._audio_callback
):
while not self.stop_event.is_set():
sd.sleep(100)
def _audio_callback(self, indata, frames, time, status):
"""
音声入力のコールバック関数
"""
if status:
print(status)
self.audio_queue.put(indata.copy())
def _recognize_audio(self):
"""
連続的な音声認識スレッド
"""
while not self.stop_event.is_set():
try:
audio_chunk = self.audio_queue.get(timeout=0.5)
if self.recognizer.AcceptWaveform(audio_chunk.tobytes()):
result = json.loads(self.recognizer.Result())
text = result.get('text', '').strip()
if text:
print(f"{text}")
except queue.Empty:
continue
def start_recognition(self):
"""
音声認識の開始
"""
self.stop_event.clear()
self.recording_thread.start()
self.recognition_thread.start()
def stop_recognition(self):
"""
音声認識の停止
"""
self.stop_event.set()
self.recording_thread.join()
self.recognition_thread.join()
def main():
recognizer = VoskSpeechRecognizer()
try:
print("音声認識を開始します。Ctrl+Cで終了できます。")
recognizer.start_recognition()
# 無限ループを防ぐ
while True:
time.sleep(1)
except KeyboardInterrupt:
print("\n音声認識を終了します...")
finally:
recognizer.stop_recognition()
if __name__ == "__main__":
main()音声辞書と文章解析用の辞書合わせて1.6Gはメモリを消費するから、ラズパイ5のメモリが4GBでは他の機能追加していくと足りなくなるだろう、使い方次第ではsmall辞書(約50MB)でも良いかもしれないけども
admin