音声認識、LLMへのリクエストとレスポンス、text2speechを一連の流れで実行できるようにしてみた
最初はMacでやったけれども、数箇所手直しするだけでラズパイ5でもちゃんと動作、正常系だけなのでユーザエクスペリエンス的にはまだまだ改善必要ですが、
三本のコードのマージはPerplexityで実行させてます、GeminiにPythonからアクセスするためにAPIキーが必要になりますが、以下のリンクから今は無償で取得できます、APIキーはシステム環境変数に保存、他人の資産だからそれはオープンにはできない
https://aistudio.google.com/apikey
<全体のコード>
import vosk
import pyaudio
import json
import numpy as np
import sounddevice as sd
import queue
import threading
import time
import os
from dotenv import load_dotenv
import google.generativeai as genai
import subprocess
class VoskSpeechRecognizer:
def __init__(self, model_path='./vrecog/vosk-model-ja-0.22'):
# モデルの初期化
vosk.SetLogLevel(-1)
self.model = vosk.Model(model_path)
self.recognizer = vosk.KaldiRecognizer(self.model, 16000)
# キュー設定
self.audio_queue = queue.Queue()
self.stop_event = threading.Event()
# マイク設定
self.sample_rate = 16000
self.channels = 1
# スレッド準備
self.recording_thread = threading.Thread(target=self._record_audio)
self.recognition_thread = threading.Thread(target=self._recognize_audio)
def _record_audio(self):
"""
連続的な音声録音スレッド
"""
with sd.InputStream(
samplerate=self.sample_rate,
channels=self.channels,
dtype='int16',
callback=self._audio_callback
):
while not self.stop_event.is_set():
sd.sleep(100)
def _audio_callback(self, indata, frames, time, status):
"""
音声入力のコールバック関数
"""
if status:
print(status)
self.audio_queue.put(indata.copy())
def _recognize_audio(self):
"""
連続的な音声認識スレッド
"""
while not self.stop_event.is_set():
try:
audio_chunk = self.audio_queue.get(timeout=0.5)
if self.recognizer.AcceptWaveform(audio_chunk.tobytes()):
result = json.loads(self.recognizer.Result())
text = result.get('text', '').strip()
if text:
print(f"認識結果: {text}")
response_text = query_gemini(text) # Gemini APIに問い合わせる
jtalk(response_text) # 結果を音声合成して再生する
except queue.Empty:
continue
def start_recognition(self):
"""
音声認識の開始
"""
self.stop_event.clear()
self.recording_thread.start()
self.recognition_thread.start()
def stop_recognition(self):
"""
音声認識の停止
"""
self.stop_event.set()
self.recording_thread.join()
self.recognition_thread.join()
def query_gemini(prompt):
"""
Gemini APIに問い合わせて応答を取得する関数。
"""
try:
response = model.generate_content(prompt)
print(f"Gemini応答: {response.text}")
return response.text.strip()
except Exception as e:
print(f"Gemini APIエラー: {e}")
return "エラーが発生しました。もう一度試してください。"
def jtalk(text):
"""
Open JTalkでテキストを音声合成し再生する関数。
"""
open_jtalk = ['/usr/bin/open_jtalk']
mech = ['-x', '/var/lib/mecab/dic/open-jtalk/naist-jdic']
htsvoice = ['-m', '/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice']
speed = ['-r', '1.0']
outwav = ['-ow', 'out.wav']
cmd = open_jtalk + mech + htsvoice + speed + outwav
try:
proc = subprocess.Popen(cmd, stdin=subprocess.PIPE)
proc.stdin.write(text.encode('utf-8'))
proc.stdin.close()
proc.wait()
# 音声ファイルを再生する場合
subprocess.call(['aplay', 'out.wav'])
except Exception as e:
print(f"音声合成エラー: {e}")
def main():
# 環境変数からGoogle APIキーを読み込む
load_dotenv()
GOOGLE_API_KEY = os.getenv('GOOGLE_API_KEY')
if not GOOGLE_API_KEY:
print("Google APIキーが設定されていません。")
return
# Google Gemini APIの設定
genai.configure(api_key=GOOGLE_API_KEY, transport="rest")
global model # グローバル変数としてモデルを定義(query_geminiで使用)
model = genai.GenerativeModel("gemini-1.5-flash")
recognizer = VoskSpeechRecognizer()
try:
print("音声認識を開始します。Ctrl+Cで終了できます。")
recognizer.start_recognition()
# 無限ループを防ぐ(Ctrl+Cで停止可能)
while True:
time.sleep(1)
except KeyboardInterrupt:
print("\n音声認識を終了します...")
finally:
recognizer.stop_recognition()
if __name__ == "__main__":
main()
<動作例>
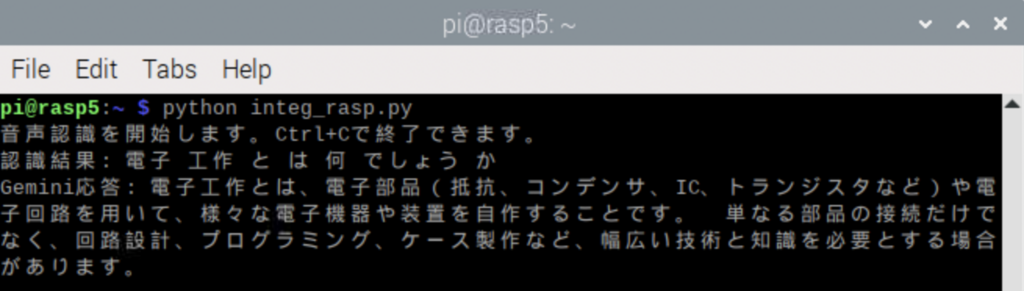
jtalkは返答の最初のブロックしか読み上げないようだけれども、長いレスポンスを全部読み上げられてもというところだから、最初だけで十分かもしれない
Geminiはマルチモーダルなので、音声認識や合成もクラウドでできそうですが、そこまでクラウドにアップロードは躊躇われるので、端末側で処理するのが妥当じゃないかと今は考えています
admin