
軽量のプラットホームであれば、パソコンでも動作可能とのことなので、M1 Mac(16GB)でポピュラーと思われるOllamaを動かしてみました、メモリは16GBはないと動きません、遅くても良いからとラズパイ5(8GB)で動かそうとしたらメモリ不足で動きませんでした
インスト方法は、モデルの変換も記述されています
https://qiita.com/s3kzk/items/3cebb8d306fb46cabe9f
OllamaはLLMのフレームワークなので実際に使うためにはモデルのインストが必要になります
<コマンドラインでのやり取りの例>
起動方法は、
% ollama run elyza:jp8b

一方APIを使う場合には、
% ollama serve
でollamaを起動しておいて、
https://highreso.jp/edgehub/machinelearning/ollamapython.html
を参考にスクリプトを作成して、
import requests
import json
url = 'http://localhost:11434/api/chat'
data = {
"model":"elyza:jp8b",
"messages": [
{
"role": "user",
"content": "千葉県の名産品を教えて、"
}
],
"stream": False
}
response = requests.post(url, data=json.dumps(data))
response_data = response.json()
print(response_data)このスクリプトを実行すると、

のようなjson形式のレスポンスが返ってきます、コンソールの対話モードに比較するとMacが考えている時間がかなり長い、おそらく10秒ちょっとかな、
リソースの消費状況は、
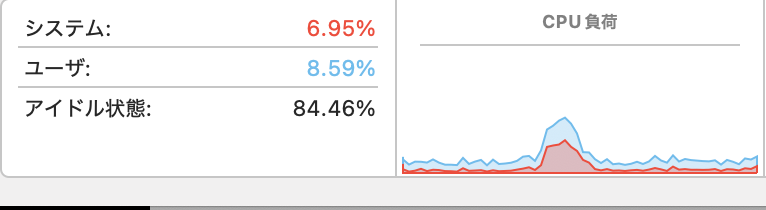
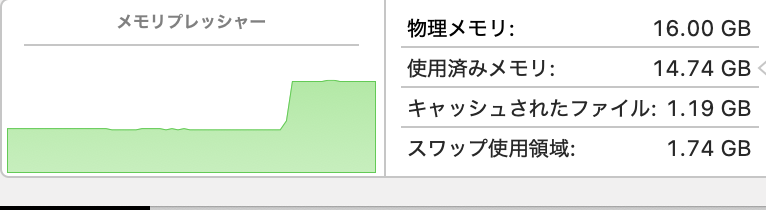
こんな感じなので、やはりラズパイ5では実用上は無理かな、
admin