生成AIでコード補完を行えるツールはいくつかありますが、オールインワンになっているのがCursorだろうと思う
UIがVScodeそのままだからエディタそのものに慣れる必要もないから使う障壁が低い、さらにはプラグイン機能もVScode用のがそのまま使えるし
Cursorにはいくつかのライセンス方式ありますが、個人で使うならばHobbyでもそこそこ使えそうだからHobby版をインストしてみた、他にはPro/Businessがあります、ここでLLMにはGemini 2.5 Flashを選択しています、無料と引き換えの情報提供はビジネスじゃないから良いかな
無料のHobby版と有料のエントリーのPro版との差異は、
https://zenn.dev/umi_mori/books/ai-code-editor-cursor/viewer/price
を参照してください
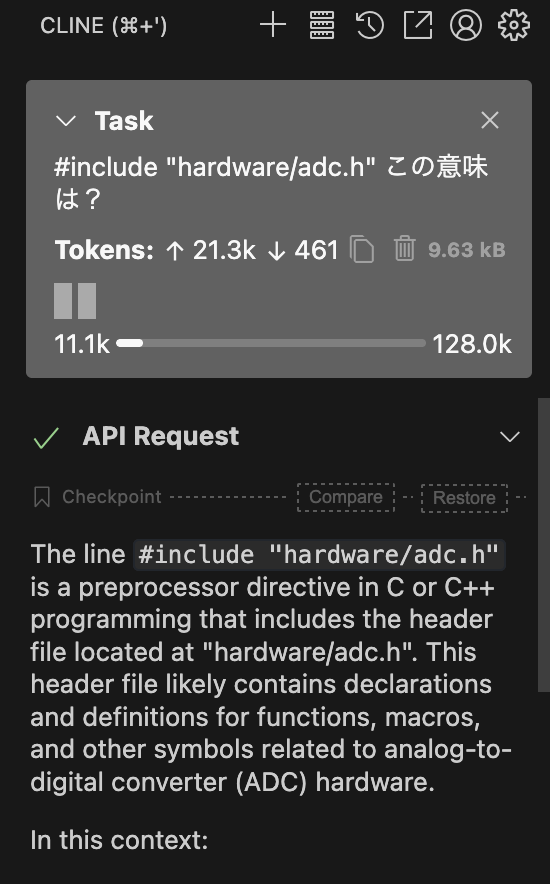
最初の一歩はHello world!的なもので、新規ファイルを作成するとプロンプトが出てくるので「golangで簡単なwebサーバーのコード作成」、そのあとで「違うディレクトリでレスポンス変えて」といって作成されたコードは以下のコード
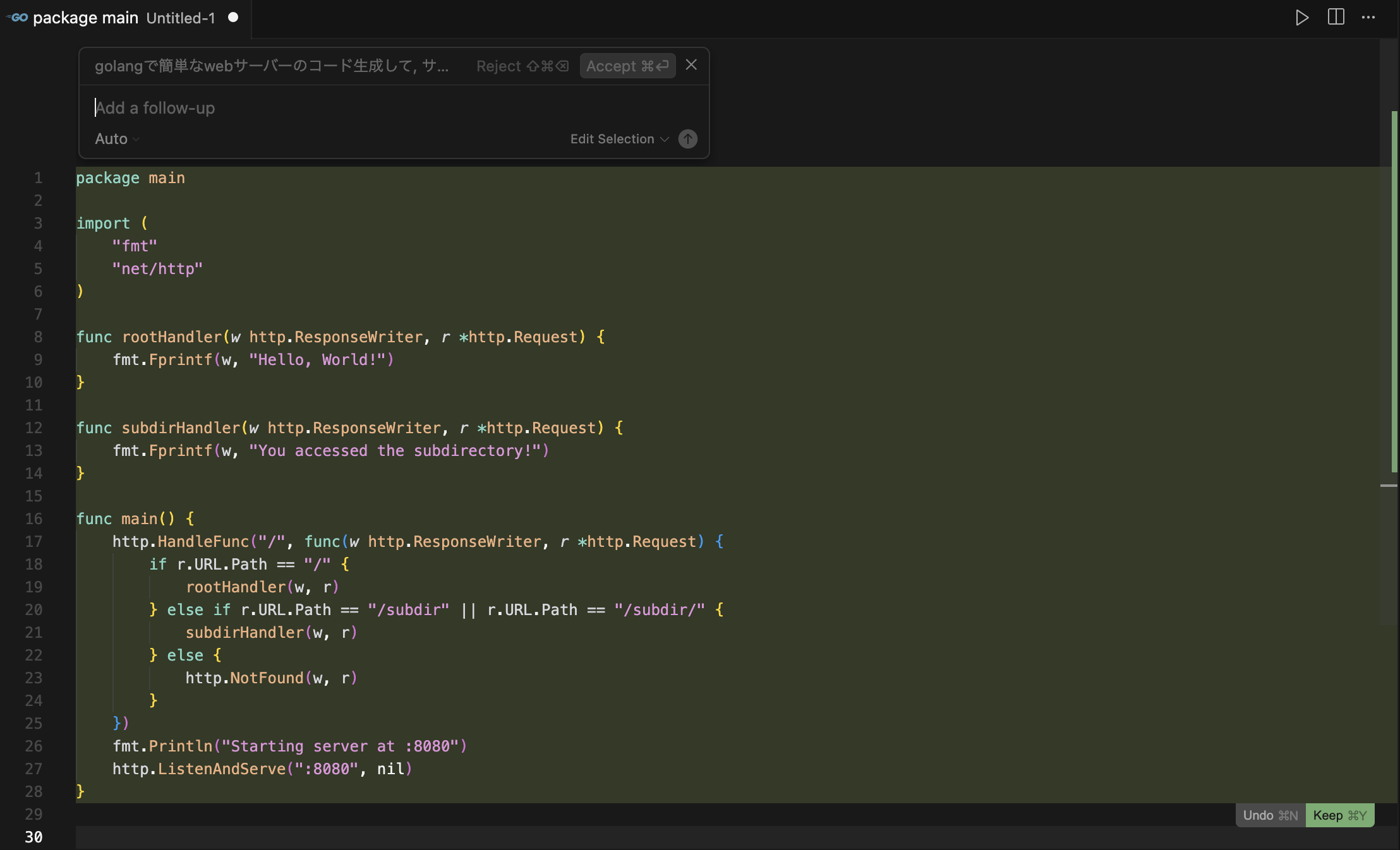
ただしGoのプロジェクトを作成したわけではないから、main.goが作成されただけ
次に既存のコード(ラズピコのpico-sdk + CMSIS dsp)を開いて、関数の解説をさせると、
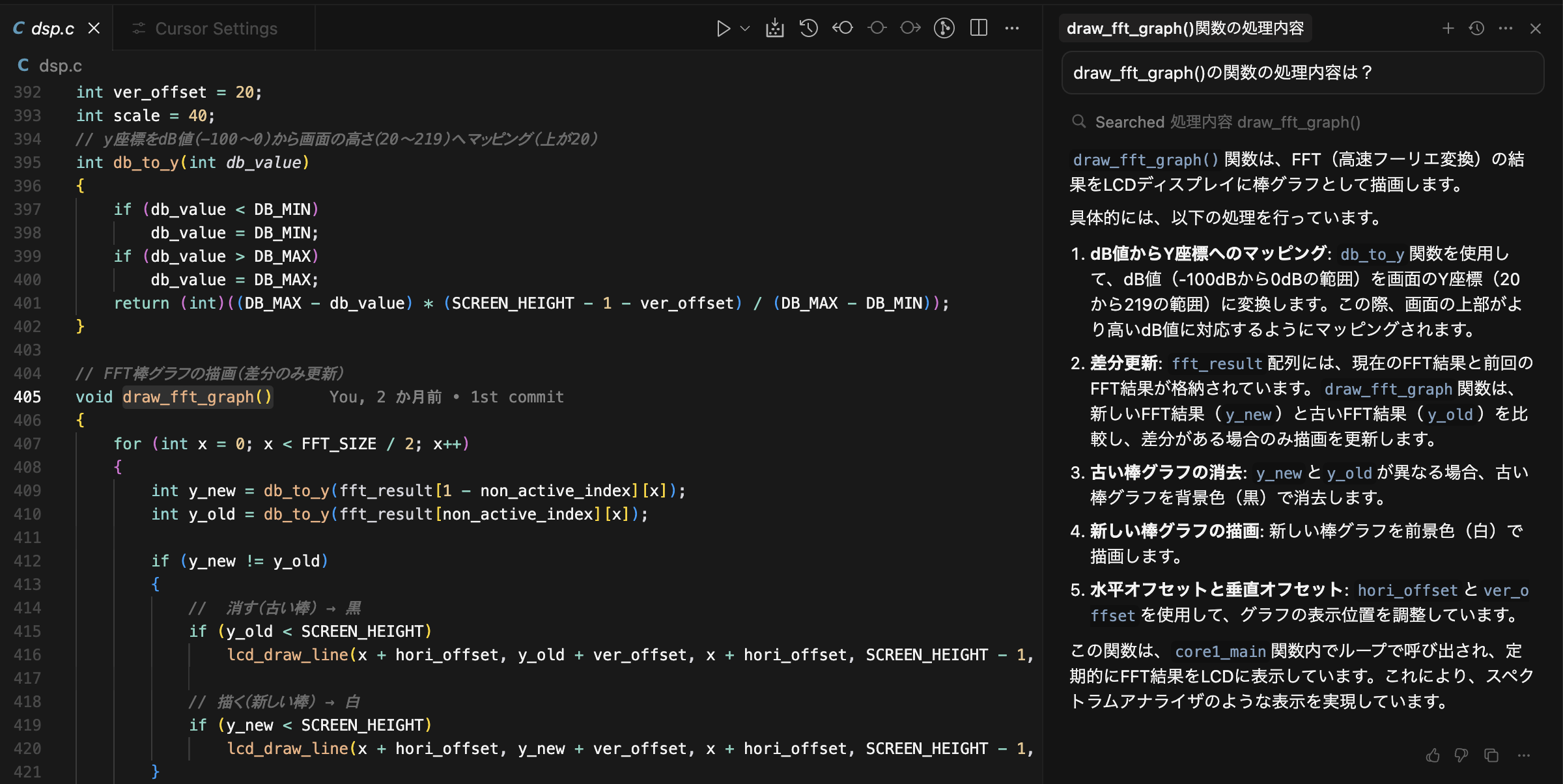
コード全体のリファクタリングしてというと、
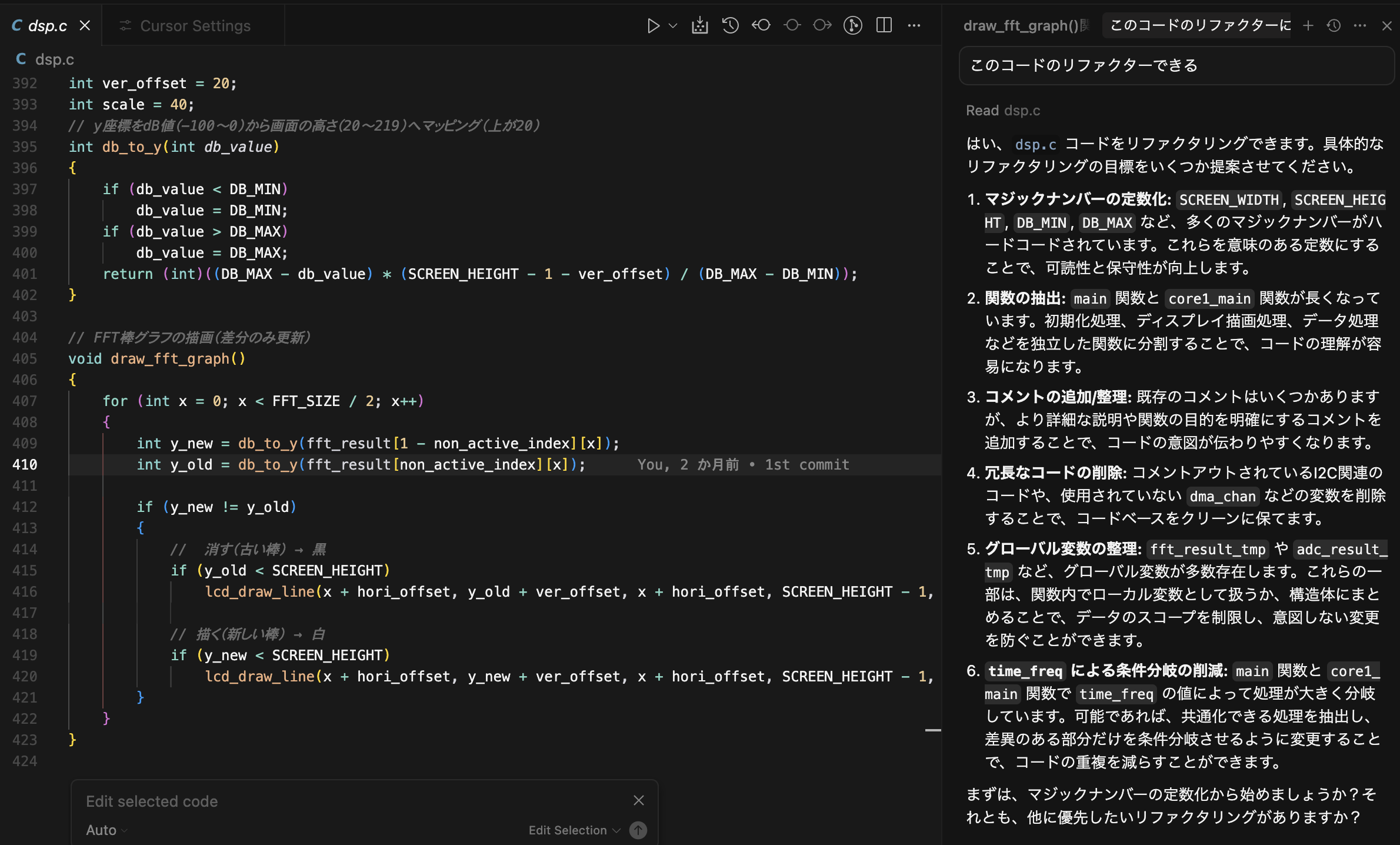
こんな感じ、
Hobby版での制限は、たまにコード書くならなんとか使えるかなというレベルですかね、仕事で使う人は間違いなくPro以上の選択になります
この領域の進歩は日進月歩だから、このレベルの機能はそれほど遠くなく無償化されるように落ちてくるように思う
admin