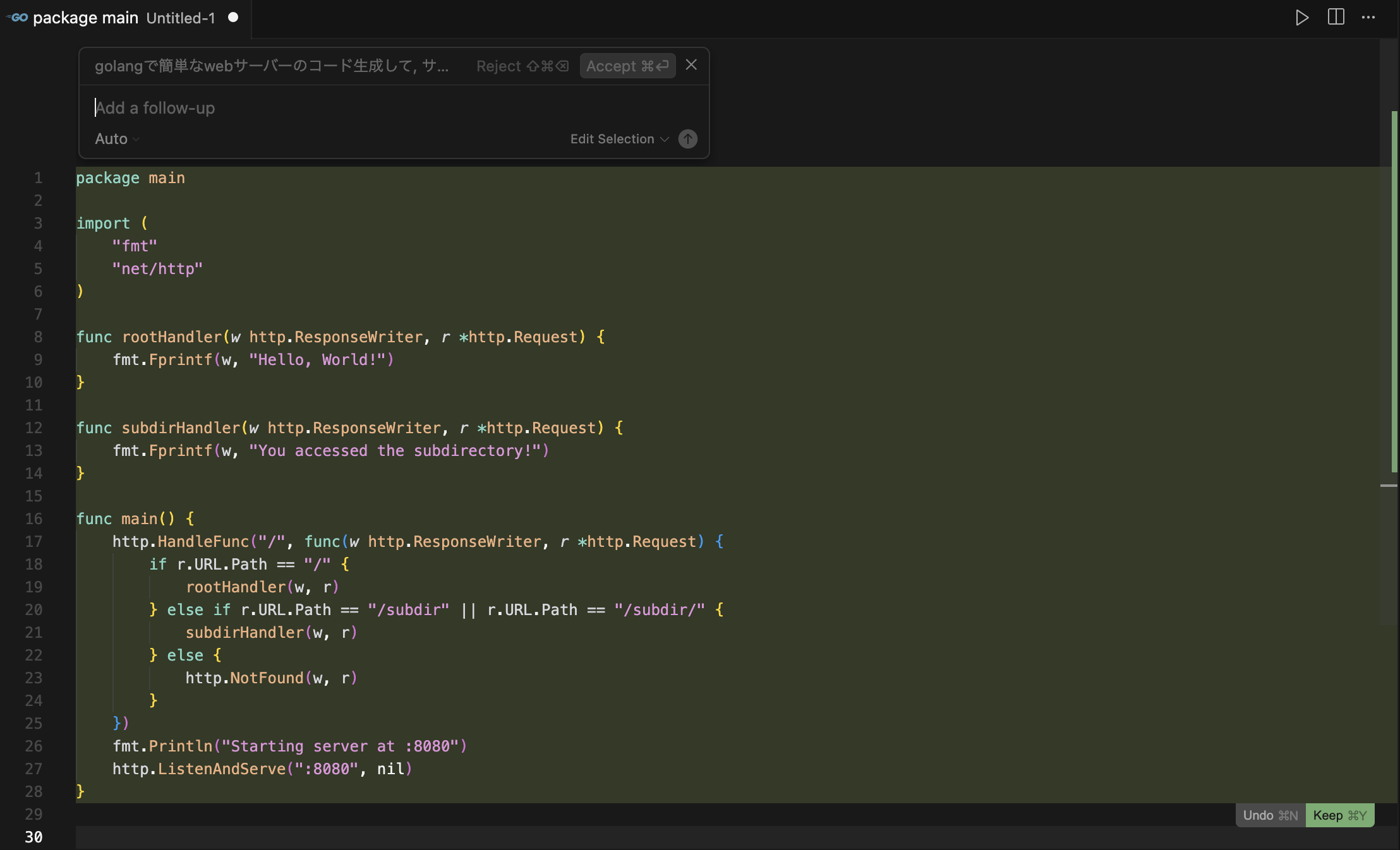
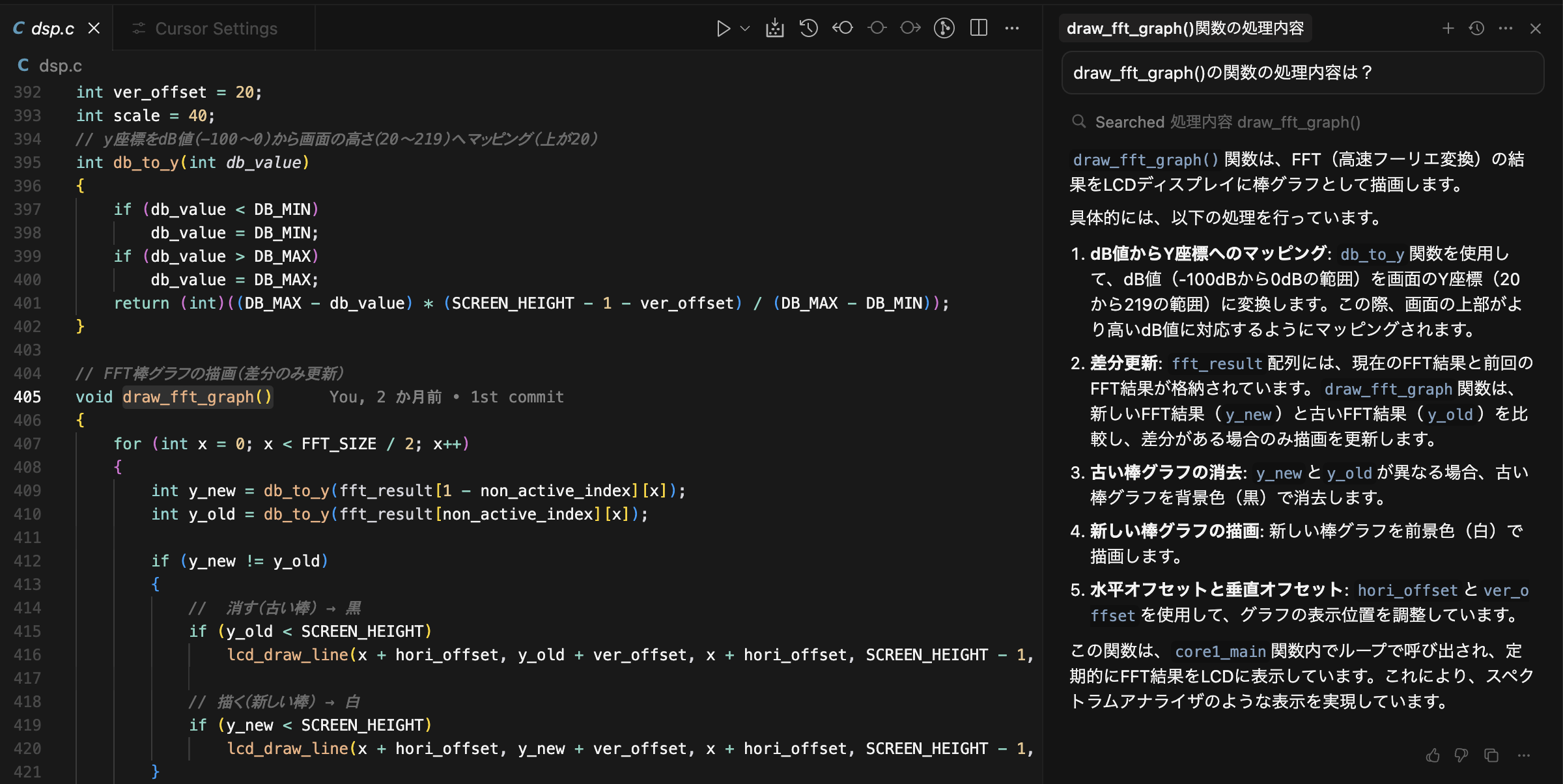
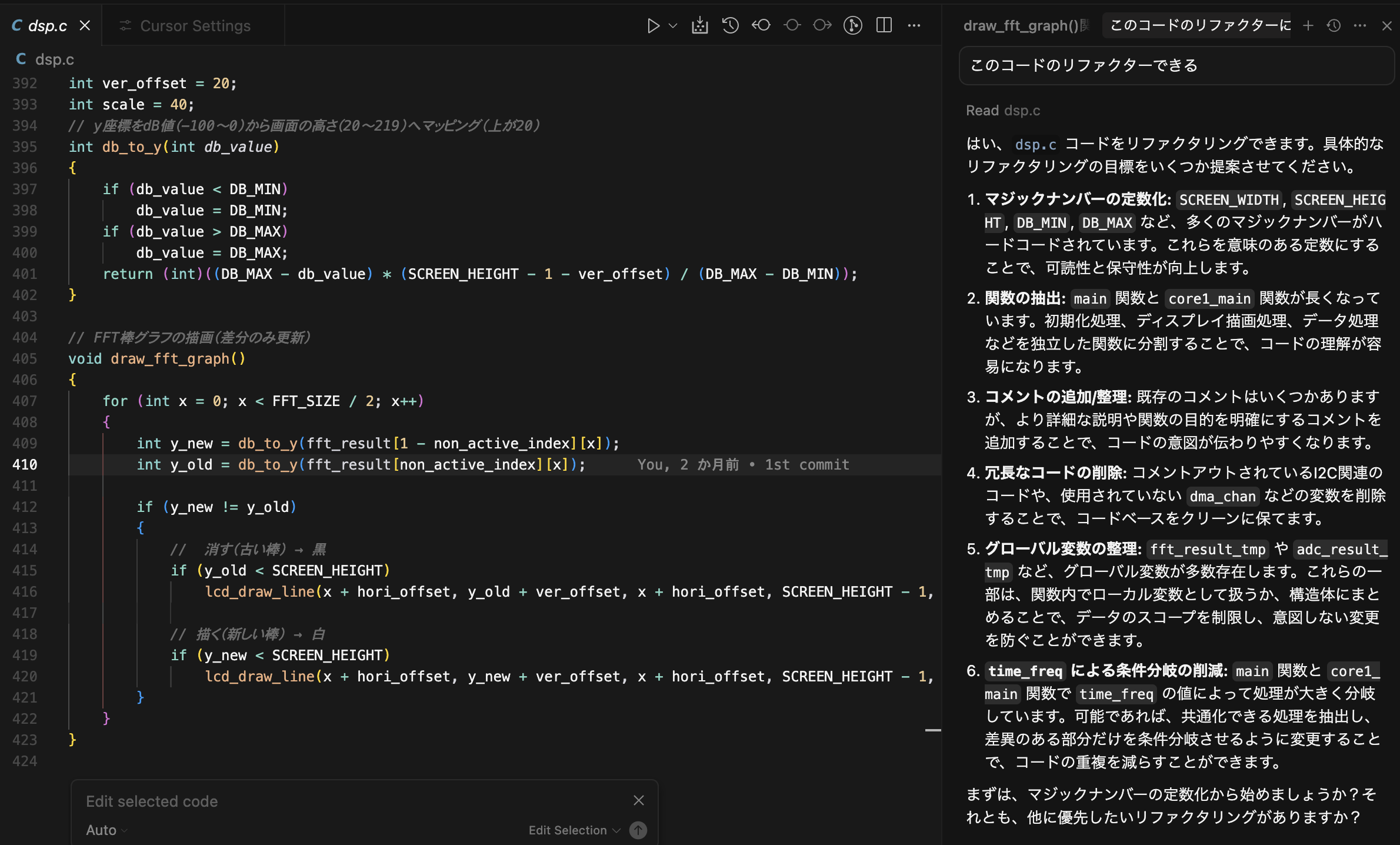
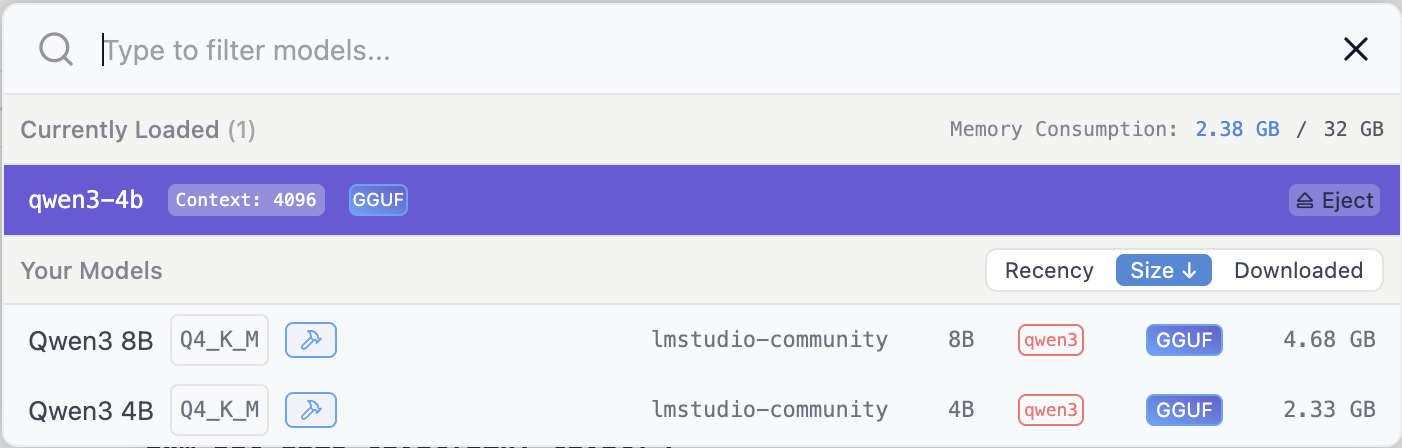
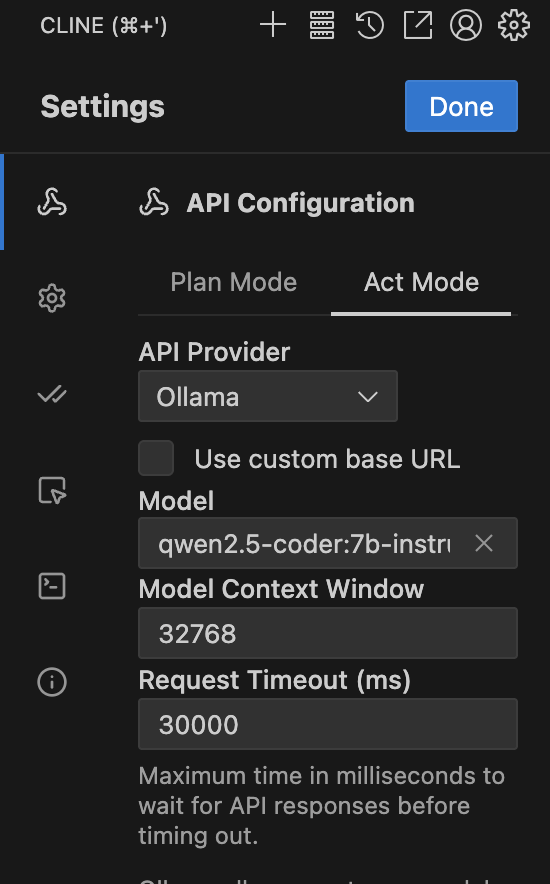
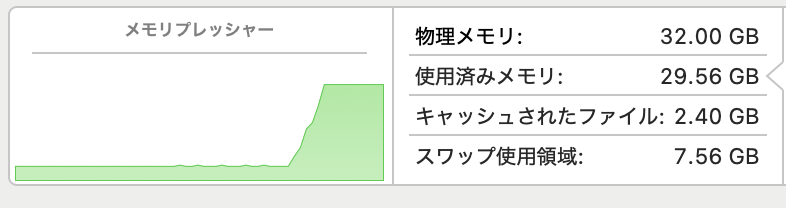
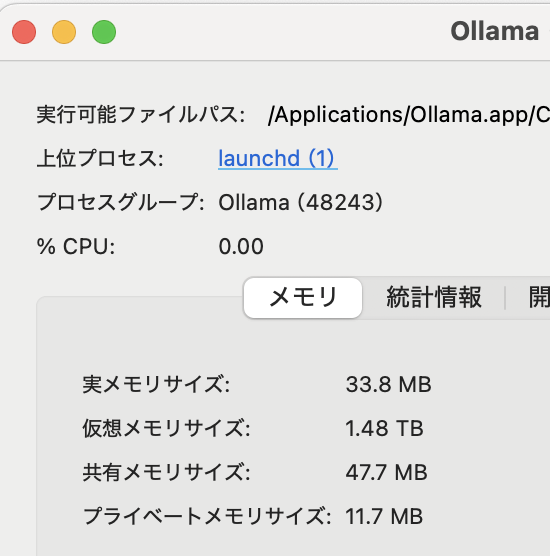
ローカルで動かせて、かつカスタマイズが簡単(ノーコードで実現可能)なLLM(モデルプロバイダを設定)が使えるプラットホームです、Webページのこのメッセージが全てかもしれません、一番特徴的なのはRAGエンジンじゃないかと思いますね
============
『DifyはオープンソースのLLMアプリ開発プラットフォームです。RAGエンジンを使用して、エージェントから複雑なAIワークフローまでLLMアプリを編成します。』
============
<インストール>
・ターゲット:M4 MacBook Pro 14
・Docker :Engine: 28.0.1/Compose: v2.33.1-desktop.1
わざわざカスタムインストの意味はないから、Docker使って素直にインストします、以下にはRancher Desktopでインスト時のメモも残ってますが、ともかく4行のコマンド実行でDockerで動くようになります
% git clone https://github.com/langgenius/dify.git
% cd dify/docker
% cp .env.example .env # 環境変数のコピー
# Rancher Desktopの場合には、
# Docker-compose.yamlの修正、ブラウザポートの重複回避のためにポート番号を変更(8888に)、661行目でした(@2015/3/16)
- '${EXPOSE_NGINX_PORT:-8888}:${NGINX_PORT:-80}'
# 注)Rancher Desktopで再インストするとアクセスできない(8888開かない?)
% docker compose up -d
# デタッチモードでバックグランドで起動させる
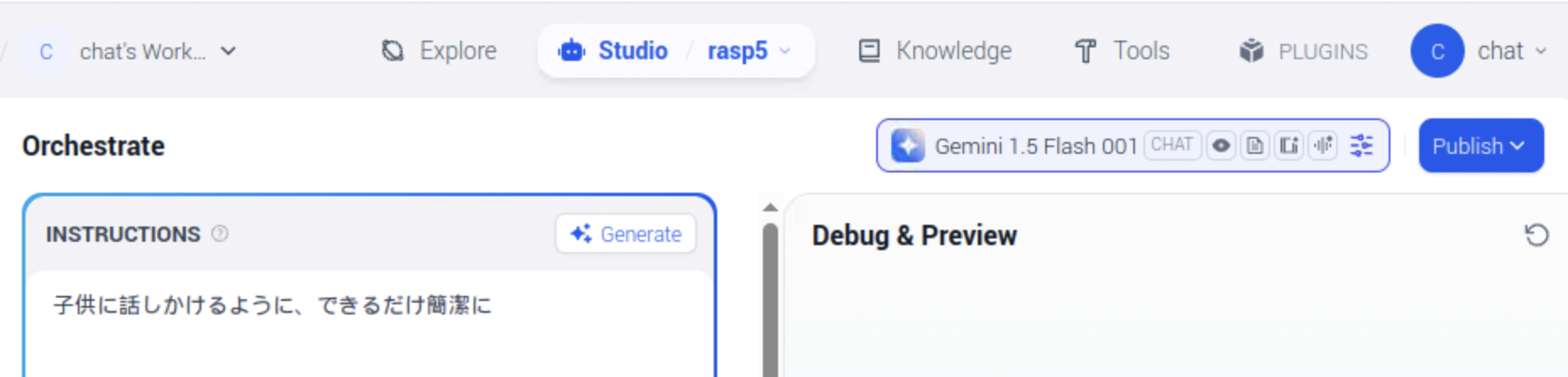
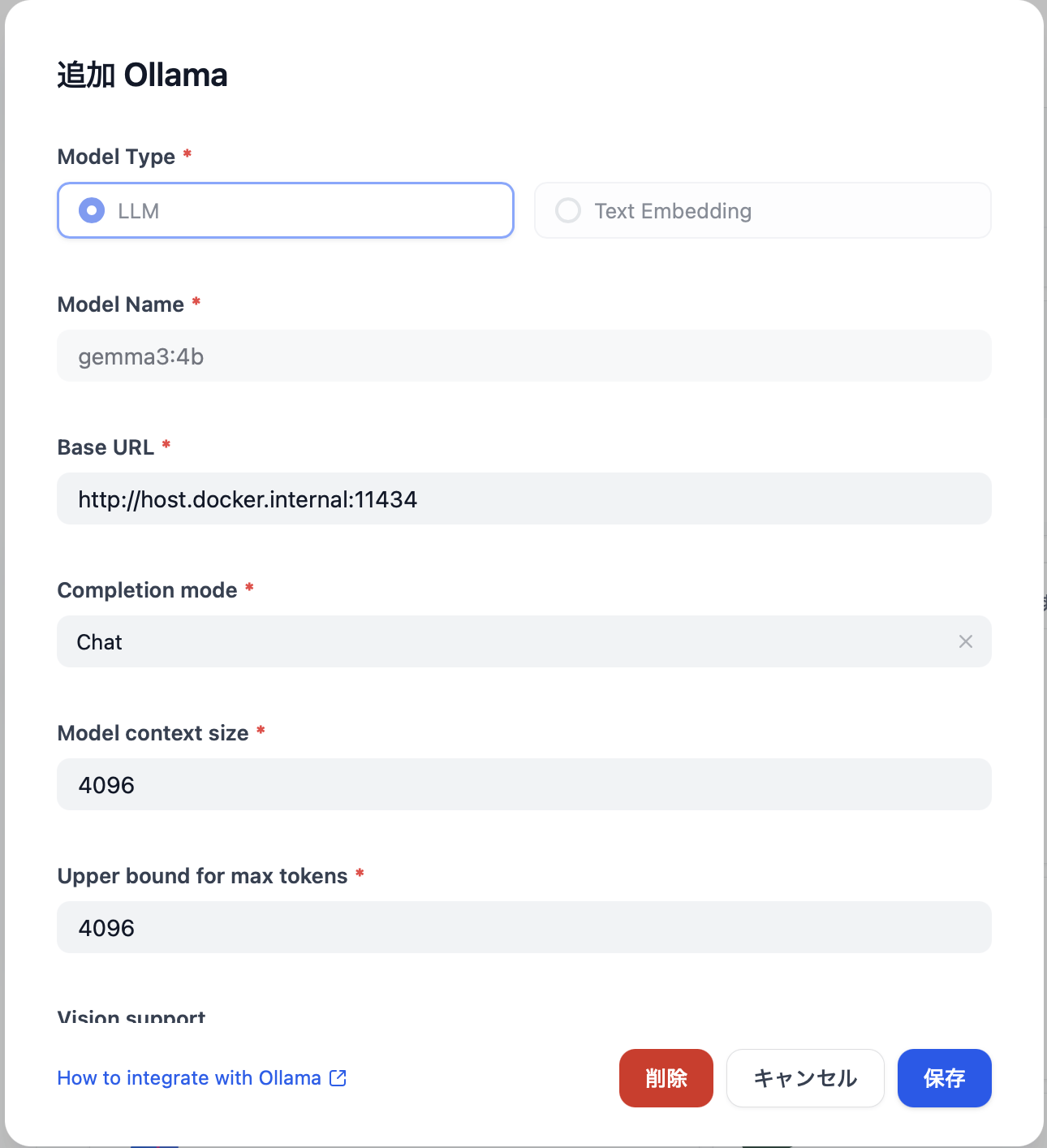
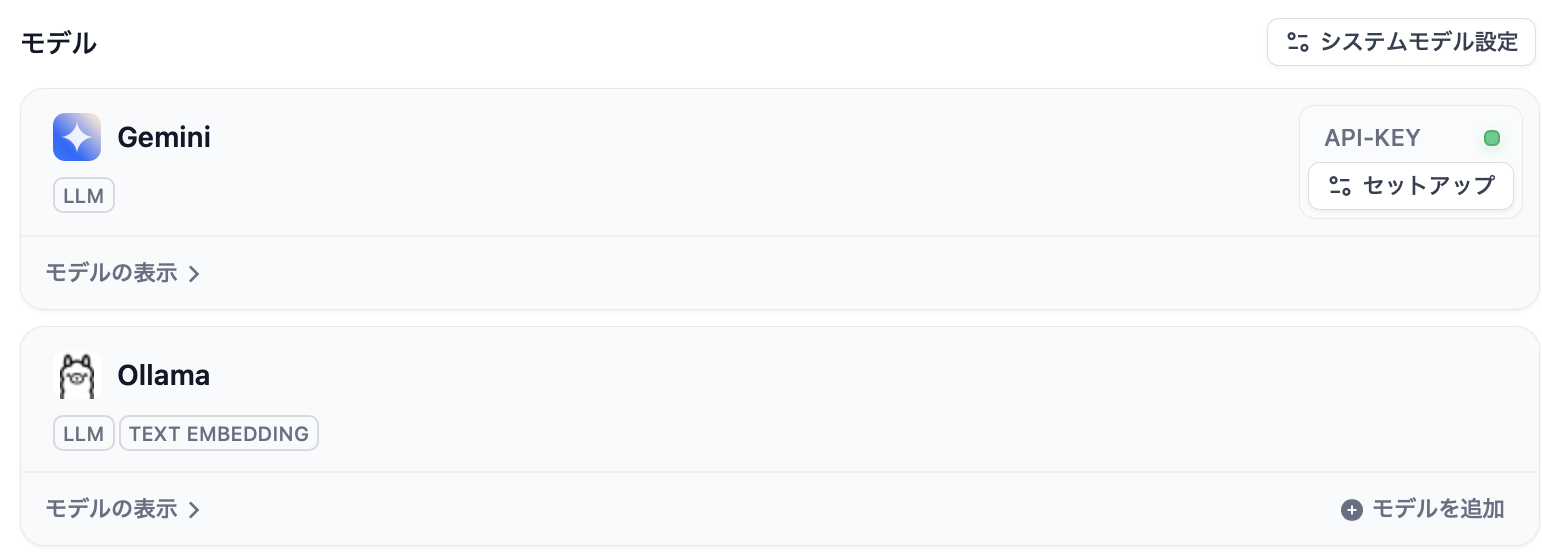
Dify自体にLLM機能はなく外部サービスを利用する形態なので、モデルプロバイダーはGeminiを設定しています
DockerとRancher Desktop両方を動かす時の切り替え方法と再インストール他のコマンド
% docker compose up --build
# imageの再ビルドを行う
% docker compose down
# containerを停止すると共に削除する
% docker compose down --rmi all
# これはimageを削除する
% docker compose stop(コンテナ停止)、start(コンテナ起動)
# Dockerの切り替え(Baker link. Env用にrancher desktopを優先させる)
% docker context use rancher-desktop
% docker context ls
NAME DESCRIPTION DOCKER ENDPOINT ERROR
default Current DOCKER_HOST based configuration unix:///var/run/docker.sock
desktop-linux Docker Desktop unix:///Users/usamiryuuichi/.docker/run/docker.sock
rancher-desktop * Rancher Desktop moby context unix:///Users/usamiryuuichi/.rd/docker.sock
% docker context use desktop-linux # change to Docker
インストールから基本的な操作(応答を変化させるオーケストレーションとか)は以下のリンクで、
https://weel.co.jp/media/dify-local/
<Pythonから使う>
RAGはとりあえず置いといて、Pythonからの使い方
クラウドのDify使う時には、
https://zenn.dev/fa18kouki/articles/579ef29527a5d9
が参考になりますが、これをローカルに置き換えてます
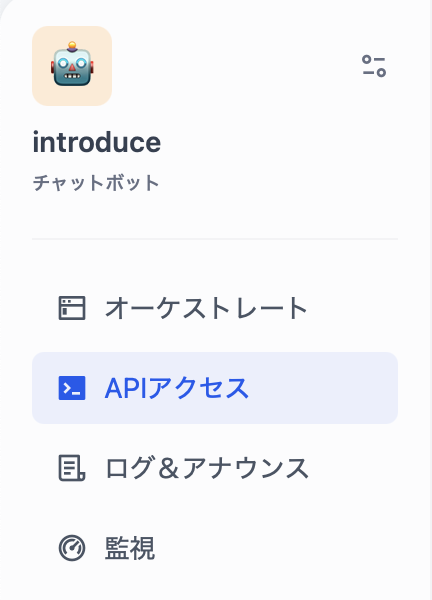
APIキーは、以下の「APIアクセス」から取得します、また具体的なAPIの使い方ドキュメントも含まれます
import requests
import json
from typing import Dict
# Dify APIの認証キー
API_KEY = 'your API key' # 取得したAPIキーに置き換えてください
# Dify APIのベースURL(ポート番号を含む)
BASE_URL = 'http://localhost/v1/chat-messages'
def get_dify_response(query: str, user: str) -> str:
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
data: Dict[str, any] = {
"inputs": {},
"query": query,
"response_mode": "streaming",
"conversation_id": "",
"user": user,
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
]
}
try:
response = requests.post(BASE_URL, headers=headers, json=data, stream=True)
response.raise_for_status()
# ここでエンコーディングを明示的に指定
response.encoding = 'utf-8'
full_response = ""
for line in response.iter_lines():
if line:
decoded_line = line.decode('utf-8')
if decoded_line.startswith("data: "):
json_data = json.loads(decoded_line[6:])
if json_data.get('event') == 'message':
raw_answer = json_data.get('answer', '')
# Unicodeエスケープのデコードを削除(不要)
print(raw_answer, end='', flush=True)
full_response += raw_answer
print()
return full_response
except requests.RequestException as e:
print(f"リクエストエラー: {e}")
return str(e)
except json.JSONDecodeError as e:
print(f"JSON解析エラー: {e}")
return "JSONの解析に失敗しました"
except Exception as e:
print(f"予期せぬエラー: {e}")
return str(e)
def main():
query = "Difyでできることは?"
user = "user0"
print("Difyへのクエリ:", query)
answer = get_dify_response(query, user)
print("\nDifyからの完全な応答:")
print(answer)
if __name__ == "__main__":
main()
エンドポイント(サービスの種類)はいくつかありますが、ここではBASE_URL = 'http://localhost/v1/chat-messages'を使っています
レスポンスは、以下のような内容で返ってきます
Difyへのクエリ: Difyでできることは?
Difyって、すごい魔法のツールなんだ!
Difyは、色々なことができるよ。たとえば、
* **お話を書く**
Difyに「お姫様とドラゴンのお話を作って」ってお願いすると、面白いお話を作ってくれるんだ!
* **絵を描く**
Difyに「虹色の猫の絵を描いて」ってお願いすると、カラフルな猫の絵を描いてくれるよ!
* **音楽を作る**
Difyに「楽しい音楽を作って」ってお願いすると、リズムの良い音楽を作ってくれるんだ!
* **ゲームを作る**
Difyに「宝探しゲームを作って」ってお願いすると、楽しい宝探しゲームを作ってくれるよ!
Difyは、まだ成長中だけど、たくさんのことができるようになるんだって!
Difyをもっと知りたい? もっと詳しいことを教えてあげるよ!
他にどんなことができるか、聞いてみてね!
Difyからの完全な応答:
Difyって、すごい魔法のツールなんだ!
Difyは、色々なことができるよ。たとえば、
* **お話を書く**
Difyに「お姫様とドラゴンのお話を作って」ってお願いすると、面白いお話を作ってくれるんだ!
* **絵を描く**
Difyに「虹色の猫の絵を描いて」ってお願いすると、カラフルな猫の絵を描いてくれるよ!
* **音楽を作る**
Difyに「楽しい音楽を作って」ってお願いすると、リズムの良い音楽を作ってくれるんだ!
* **ゲームを作る**
Difyに「宝探しゲームを作って」ってお願いすると、楽しい宝探しゲームを作ってくれるよ!
Difyは、まだ成長中だけど、たくさんのことができるようになるんだって!
Difyをもっと知りたい? もっと詳しいことを教えてあげるよ!
他にどんなことができるか、聞いてみてね!
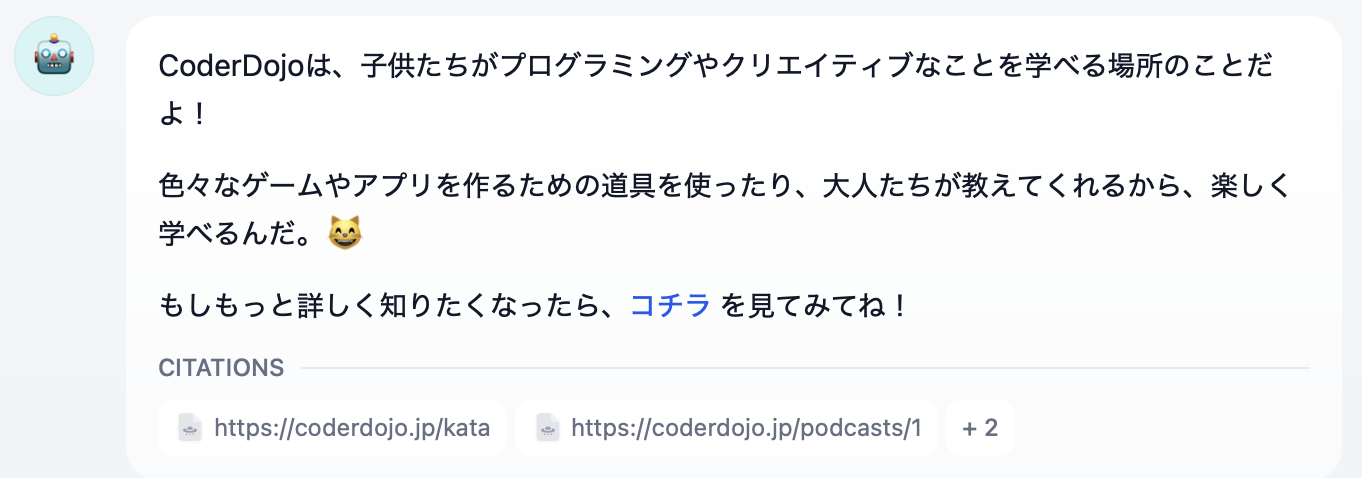
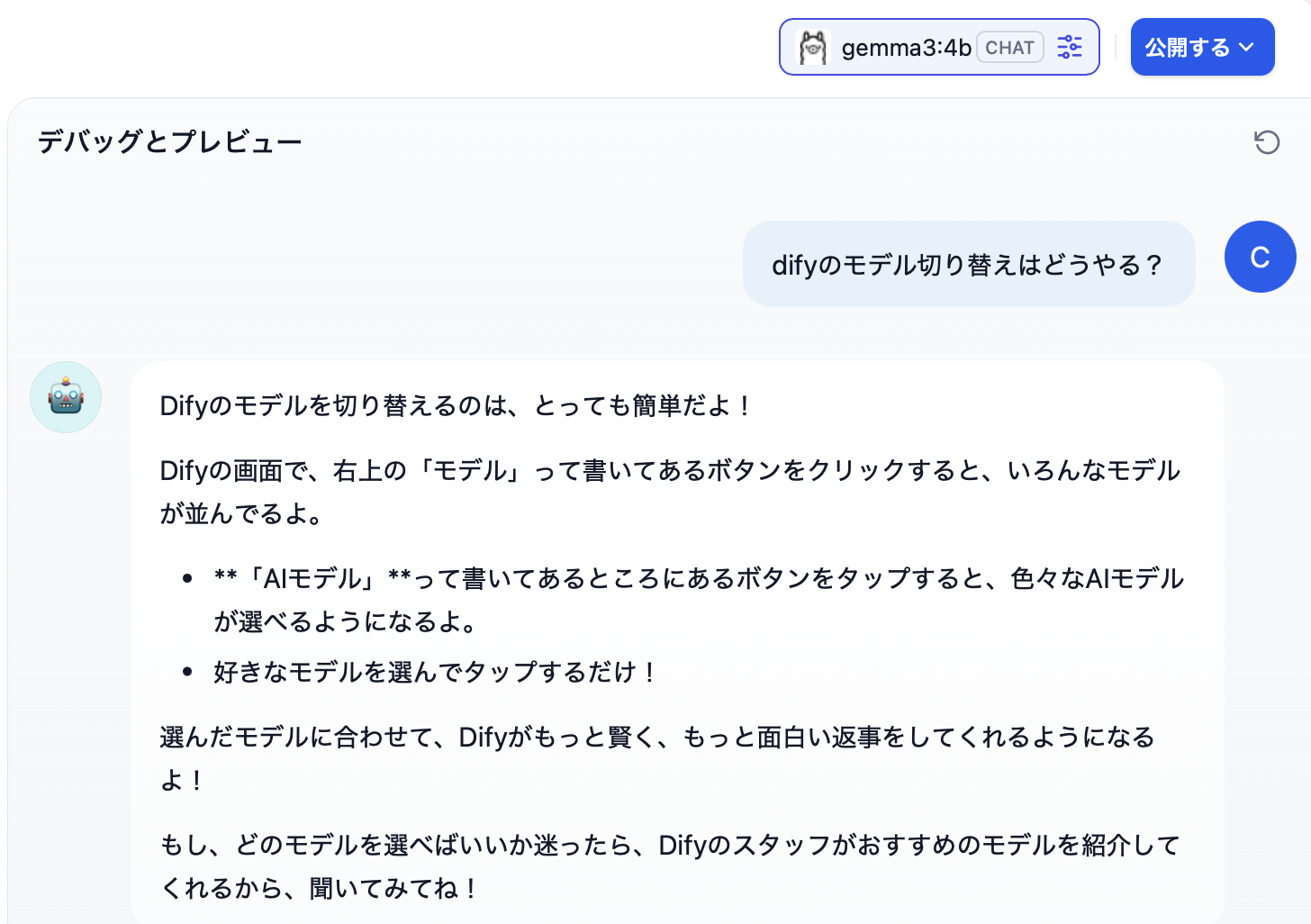
モデルプロバイダーからのレスポンスをオーケストレーション設定で「子供に話すような回答」と設定しているので、Dify内で加工されたレスポンスになっています
admin