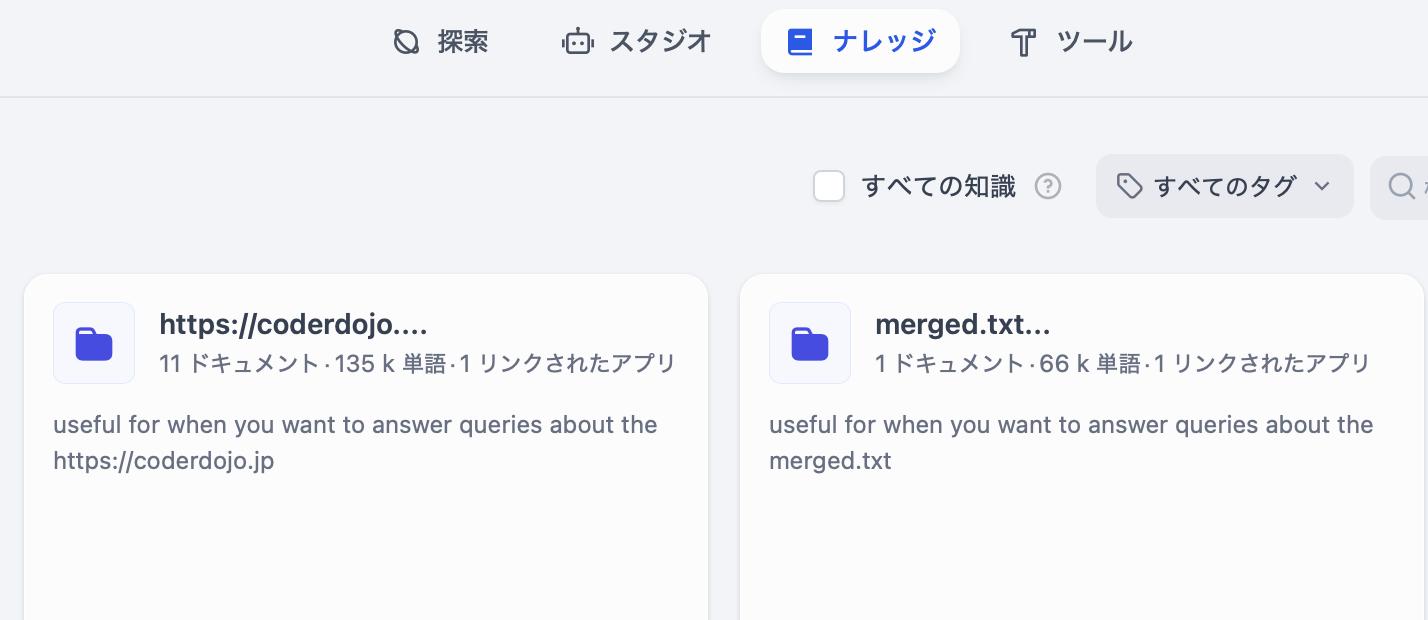
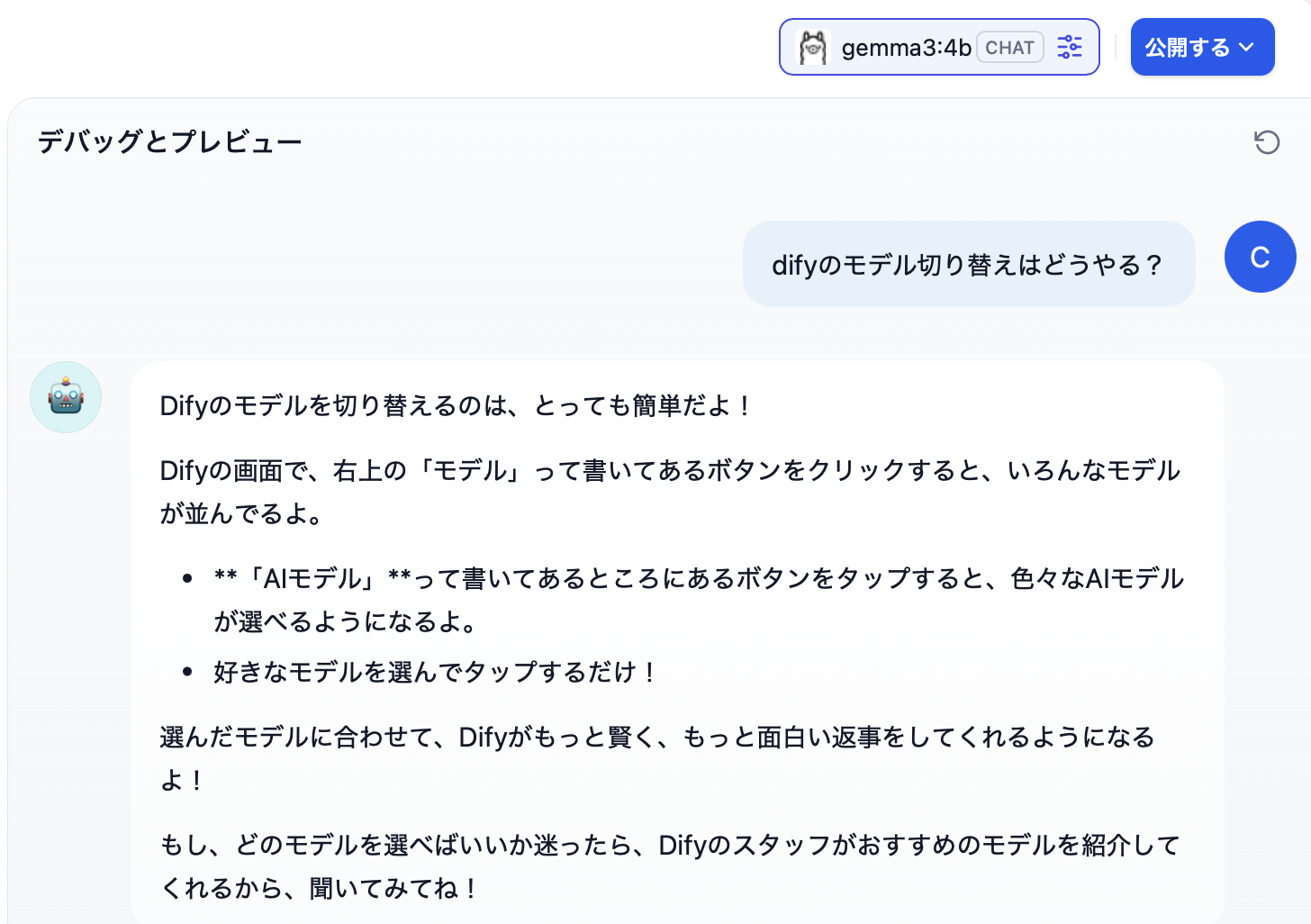
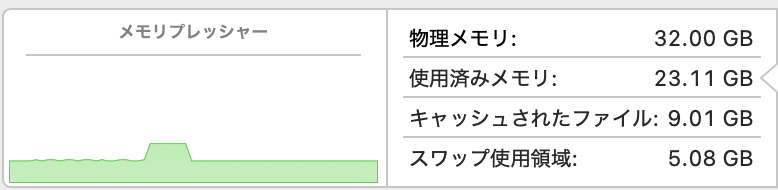
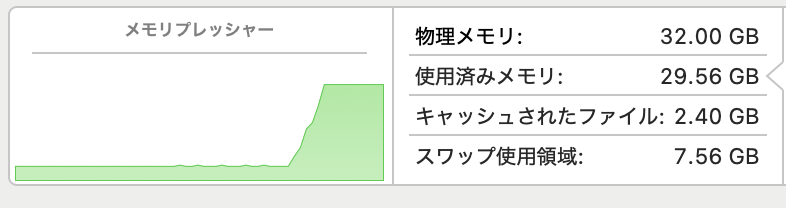
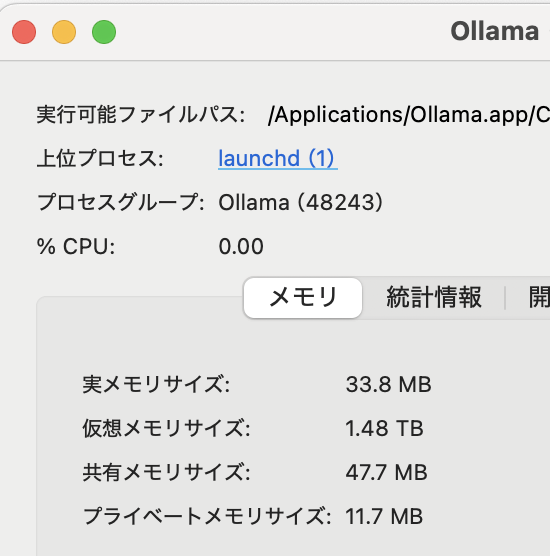
そこそこSDカードの中身も落ち着いてきて、サイズも20GB/64GBぐらいになってきたので、運用寿命と速度を勘案してSSDにしました

仕様は写真から読み取れますが、アダプタボードとNVMe仕様のSSD、サイズは256GBでおそらく一生持ちそう
ディスクの作成は、SD Card Copierを使って行いました、
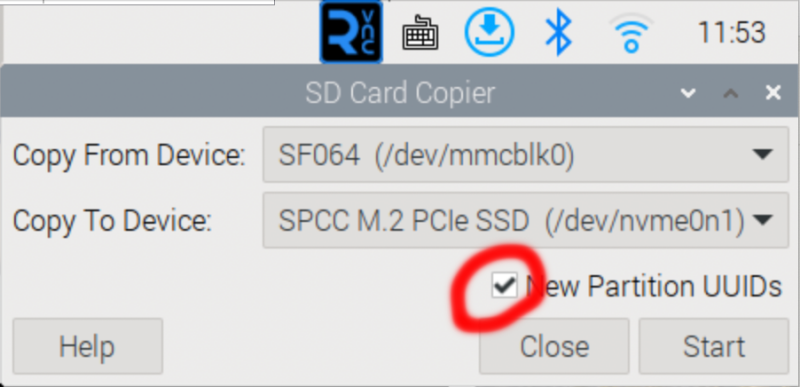
New Partition UUIDsにチェックは重要、チェックしないと完全クローンになるので、SDカードとSSD同時実装時に区別つきません
最初、チェックしないでコピーしたのでリカバリに苦労、以下LLMに聞きながら実行した手順、要は「MBR/GPTヘッダ完全削除
」をしないとダメのようです
同じUUIDでコピーした時のリカバリ手段、macで単純ディスク消去だと
MBR/GPTヘッダが残ってるらしく不完全な初期化です
$ diskutil list # SSDのドライブ番号を検索する(/dev/disk4 だった)
$ diskutil unmountDisk /dev/disk4 # 外付けSSD番号を指定
# MBR/GPTヘッダ完全削除
(初期化するからディスク名や形式は重要ではないはず)
$ diskutil eraseDisk JHFS+ NewDiskName /dev/disk4
$ sudo dd if=/dev/zero of=/dev/disk4 bs=1M count=100インストールして、bootデバイスを探す時間は無駄なのでSSDを一番最初にアクセスするような設定に変更します
$ sudo rpi-eeprom-config --edit
ファイルの461 -> 416に変更(右から順番に探して、6はSSDです)eepromへの書き込みなので変更直後に同じコマンド打っても反映されずリブートでeepromから読み込まれることで設定が反映されてることを確認できます、また編集ファイルはtmpファイルで中身の妥当性の検証を行ってから本来の設定ファイルを書き換えます
$dfの結果はこんな感じ、
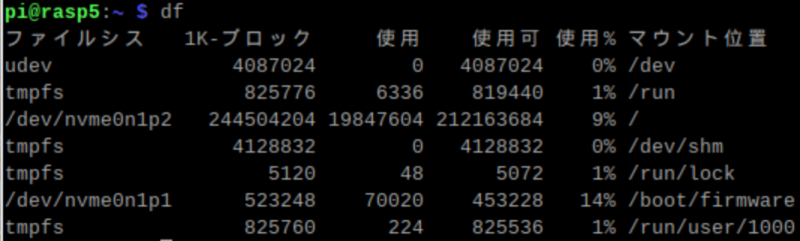
電源オン起動時間は体感でも明らかに早いし、アプリ(例えばブラウザ)の起動も早い、VNCでダミーHDMI入れてないから、相変わらずフレームレートは出ないけども
P.S. デスクアクセス性能
以前SDカードの値があったので比較してみる(上段2,530がSDカードで下段39,288がSSD)
$ sudo curl https://raw.githubusercontent.com/TheRemote/PiBenchmarks/master/Storage.sh | sudo bash
Category Test Result
HDParm Disk Read 90.82 MB/sec
HDParm Cached Disk Read 90.94 MB/sec
DD Disk Write 32.5 MB/s
FIO 4k random read 6317 IOPS (25268 KB/s)
FIO 4k random write 845 IOPS (3382 KB/s)
IOZone 4k read 29989 KB/s
IOZone 4k write 3288 KB/s
IOZone 4k random read 30032 KB/s
IOZone 4k random write 3268 KB/s
Score: 2530
Category Test Result
HDParm Disk Read 441.07 MB/sec
HDParm Cached Disk Read 432.23 MB/sec
DD Disk Write 345 MB/s
FIO 4k random read 87521 IOPS (350085 KB/s)
FIO 4k random write 85333 IOPS (341333 KB/s)
IOZone 4k read 132985 KB/s
IOZone 4k write 169992 KB/s
IOZone 4k random read 63871 KB/s
IOZone 4k random write 181370 KB/s
Score: 39288 今時のベンチマークに比較して、めちゃくちゃ早いわけではないが、妥当な値と言えるだろう
admin