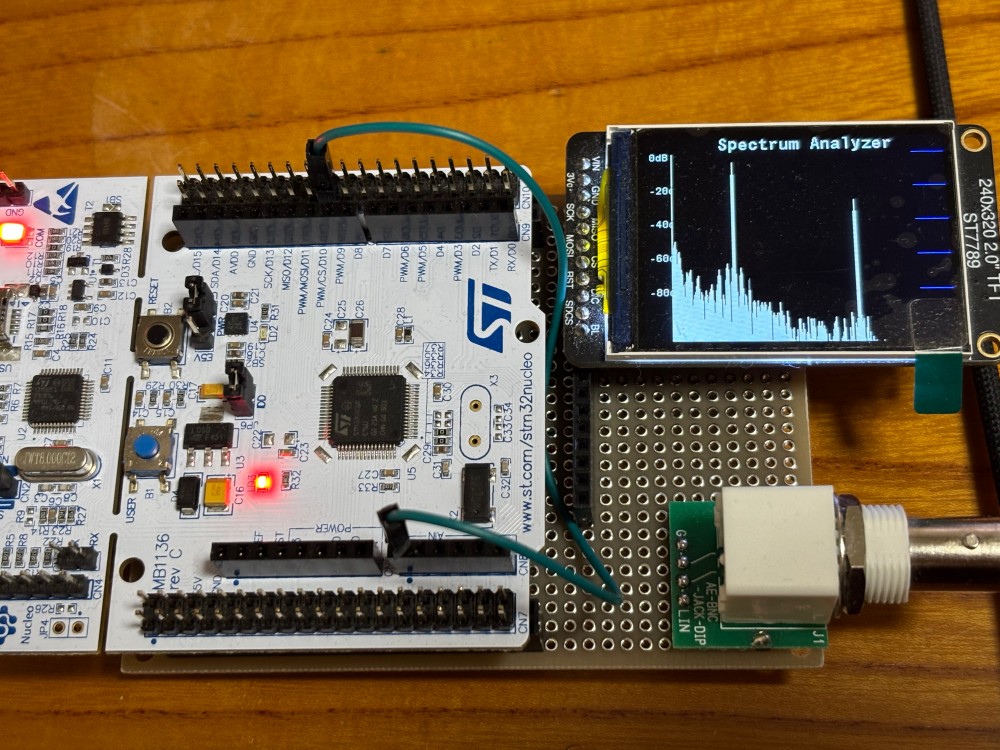
前回からの続きですが、spi LCD (320*240 : st7789)に結果を表示させます
一点ハマりどころは、ドライバーの標準サポートが240*240までのこと
https://github.com/AlexKaut/ST7789-STM32-DMA
実は単純に数字の書き換えだけではうまくいかなくて、結局数箇所変更
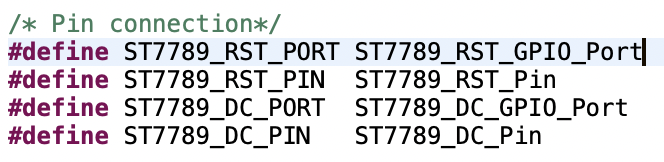
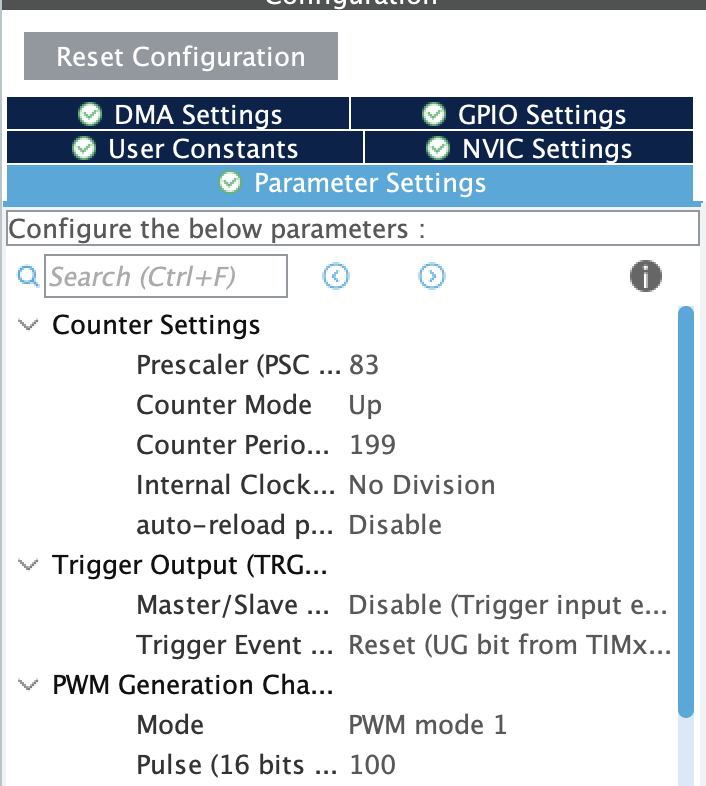
物理インターフェースはspi2使うように.hファイル変更(これは以前に実施済み)
/* choose a Hardware SPI port to use. */
#define ST7789_SPI_PORT hspi2 // to accommodate with actual usage
extern SPI_HandleTypeDef ST7789_SPI_PORT;
画面サイズの定義は、これも.hファイル変更
#ifdef USING_240X320
#if ST7789_ROTATION == 0 || ST7789_ROTATION == 2
#define ST7789_WIDTH 240
#define ST7789_HEIGHT 320
#else
#define ST7789_WIDTH 320
#define ST7789_HEIGHT 240
#endif
#define X_SHIFT 0
#define Y_SHIFT 0
#endif
に変更
初期化の処理に最後に、これは.cファイル変更
void ST7789_Init(void)
ST7789_SetRotation(ST7789_ROTATION); // to change for using 320*240 Panel
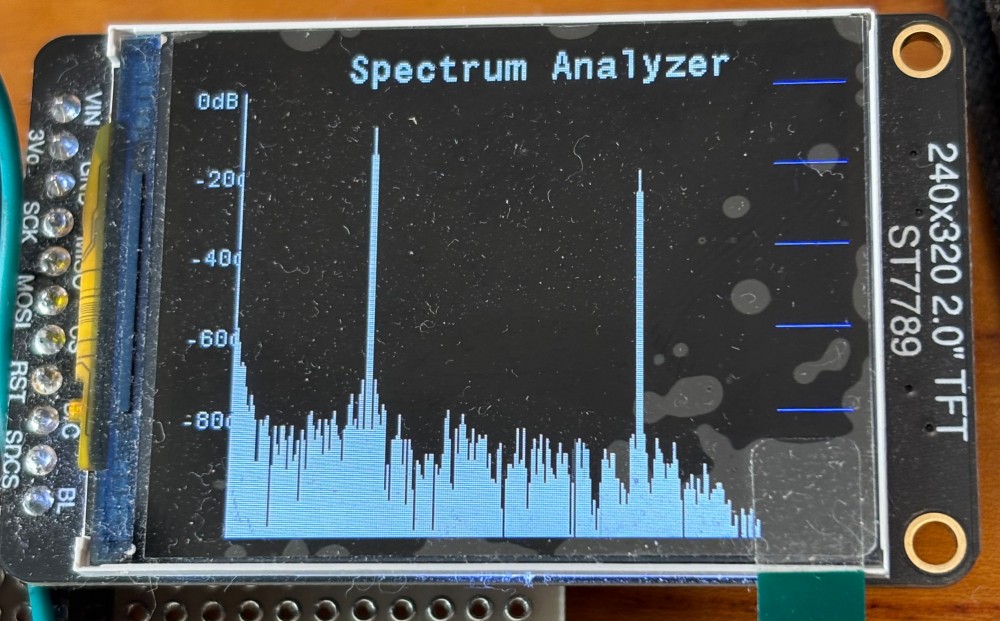
を追加、この変更で、320*240でかつローテーション表示(横方表示)ができるようになりました、結果表示はこんな感じですが、
<動画はこちら>
<気付き>
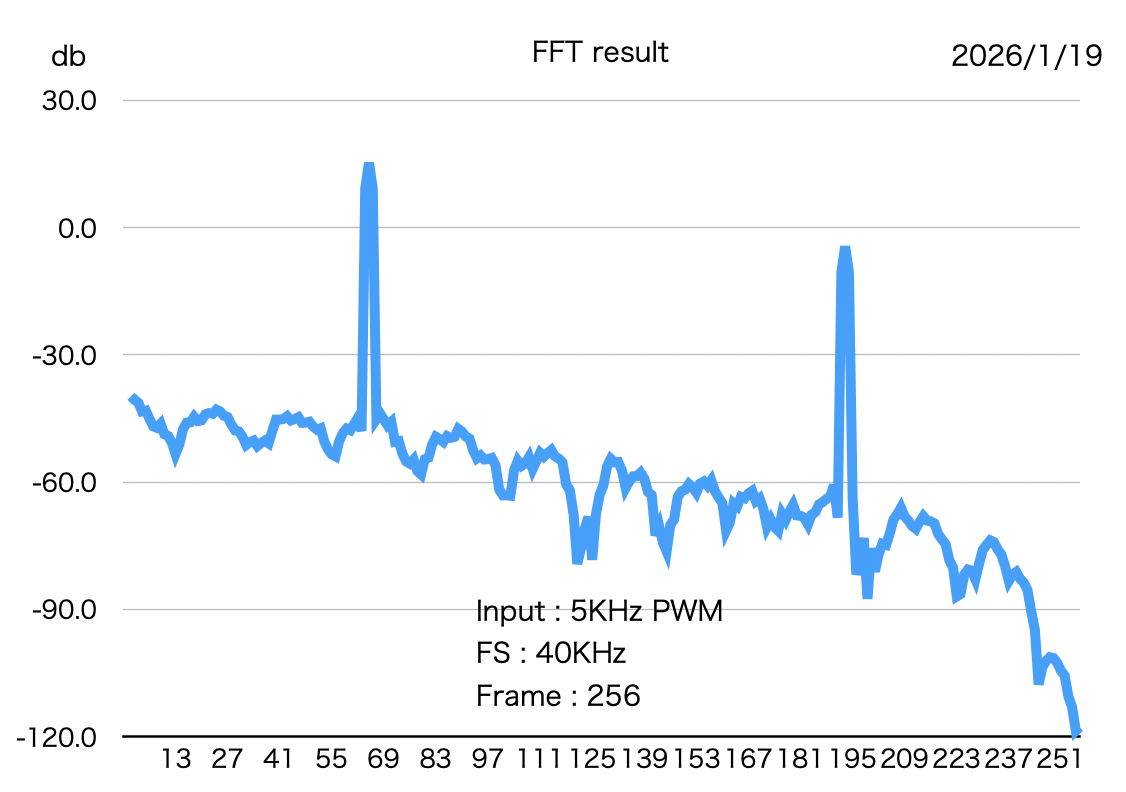
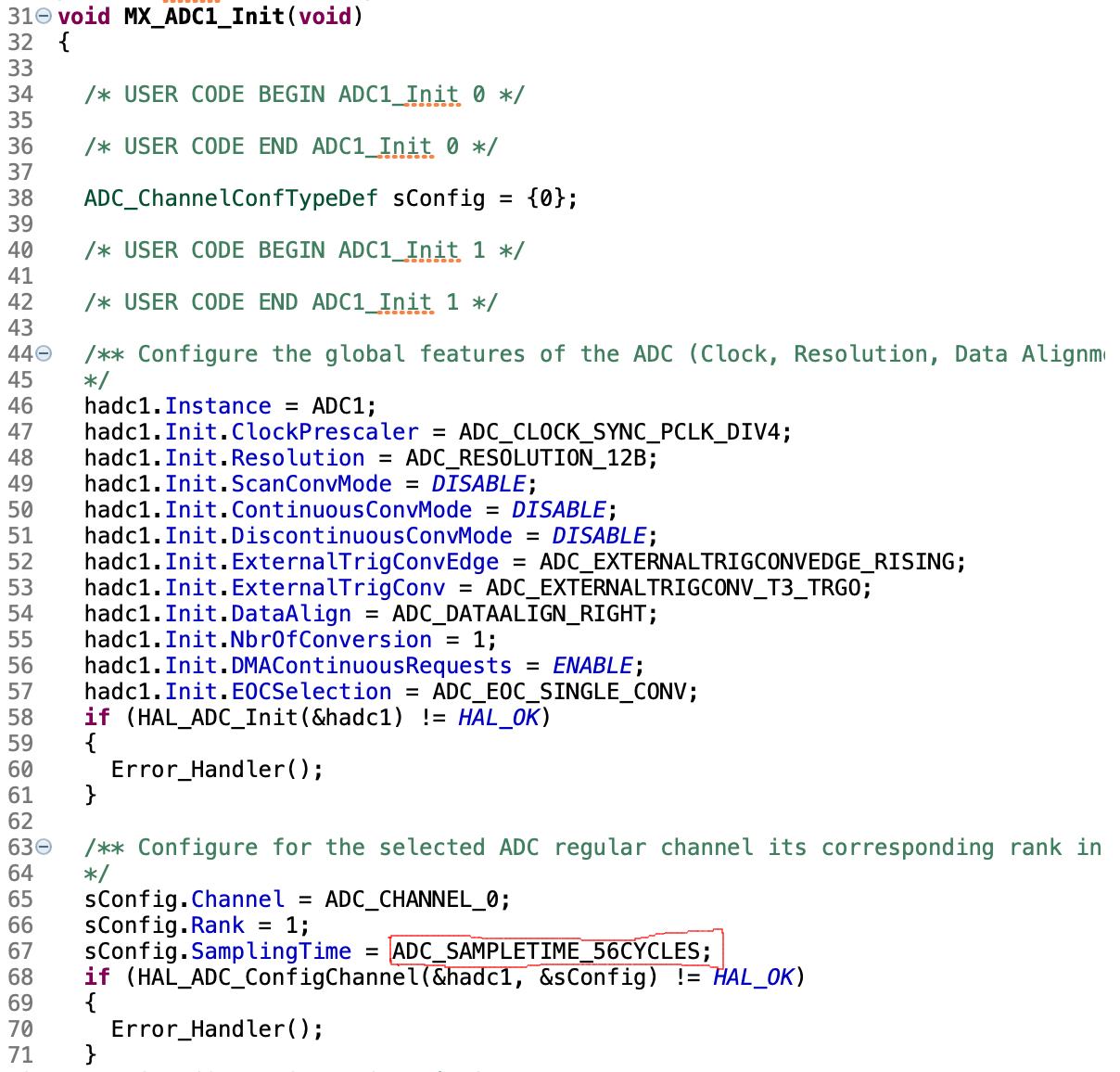
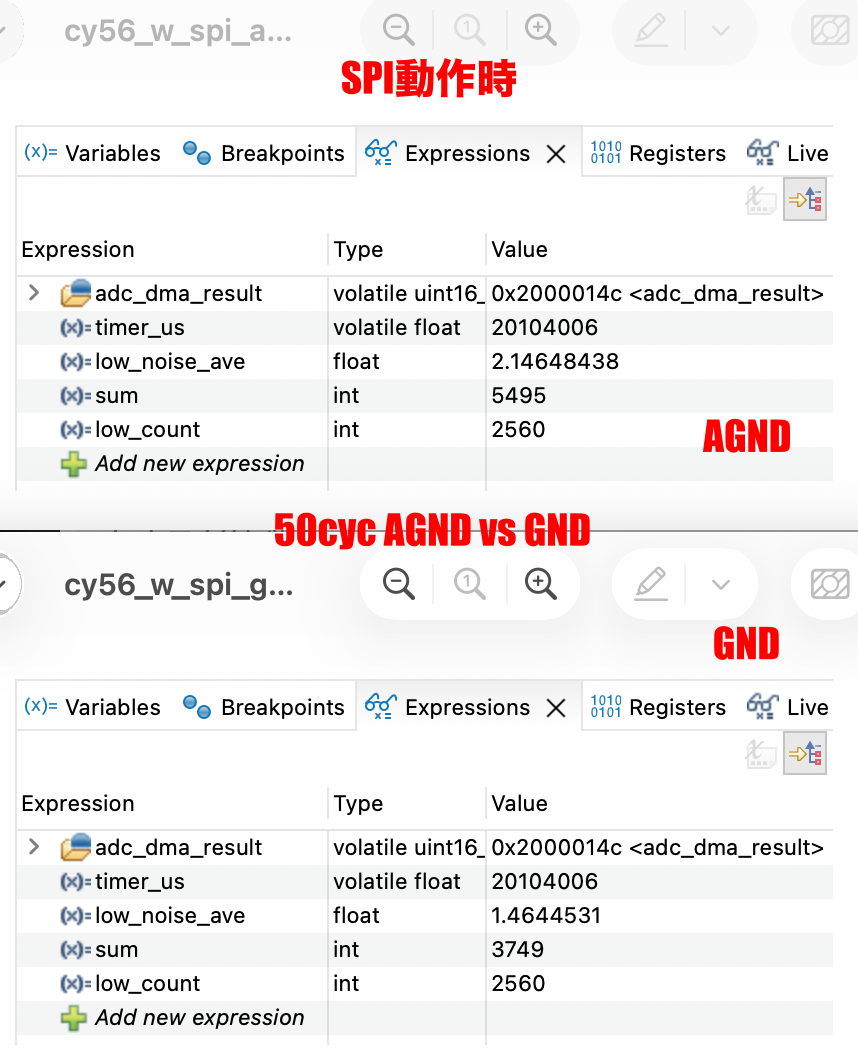
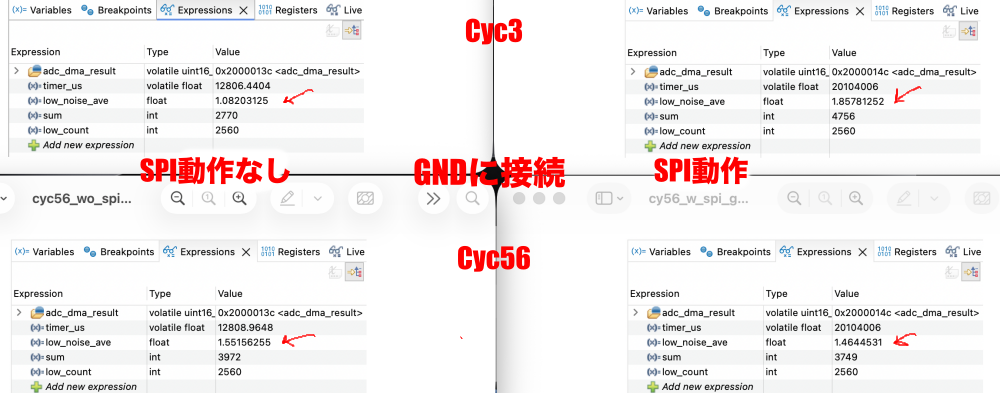
① ノイズレベルがかなり変動、それはFFT処理の中身からしてそう言うものらしいので見せるための処理、例えば平均化とかが必要、USBオシロのFFT機能で見るとフラットに見える、ただしS/Nが基本波で60db程度取れているのはほぼ同等
② 基本波と第三高調波の差が見かけ20db程度ある、入力は5KHzのDuty 50%のPWMなので理屈ではおよそ9dbぐらいの際になるはず、ノイズレベルのカーブからするとADCの入力にこんな周波数特性があるのかもしれない
–> 今の二次のIIRフィルタは15KHzで10db程度減衰することが問題なのでカットオフ20KHzの一次IIRフィルタに変更でまともそうになった、ノイズレベルも均一化してるしね
LCDへの表示処理は見かけ1秒近くかかっているので、FFT処理は比較すると瞬時
実測でFFT計算関連書処理時間はおよそ3.2ms、512samples*40Kspsだとおよそ13msなので十分にFFT処理は高速、実際のFFT計算は0.5msぐらいで完了するだろうから前後の処理が大半を占めています
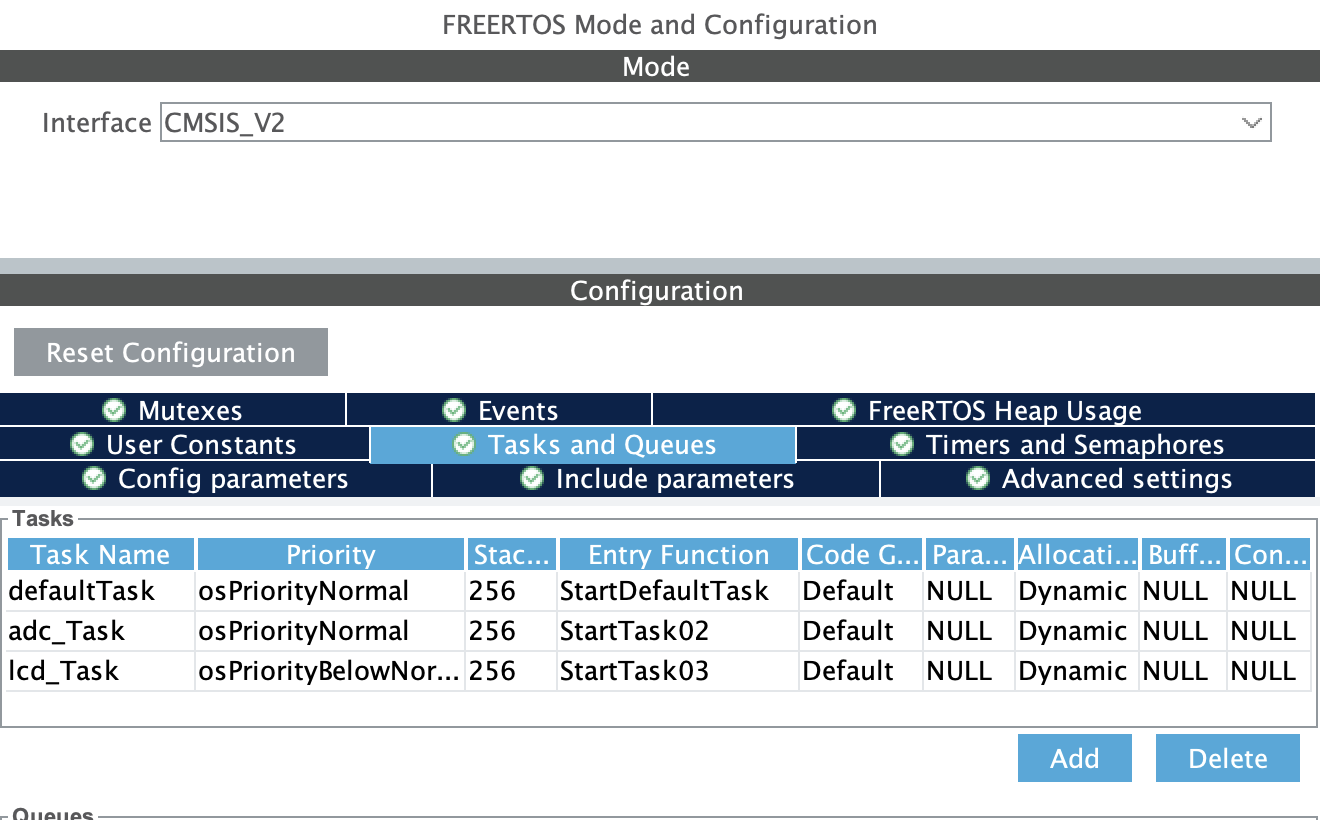
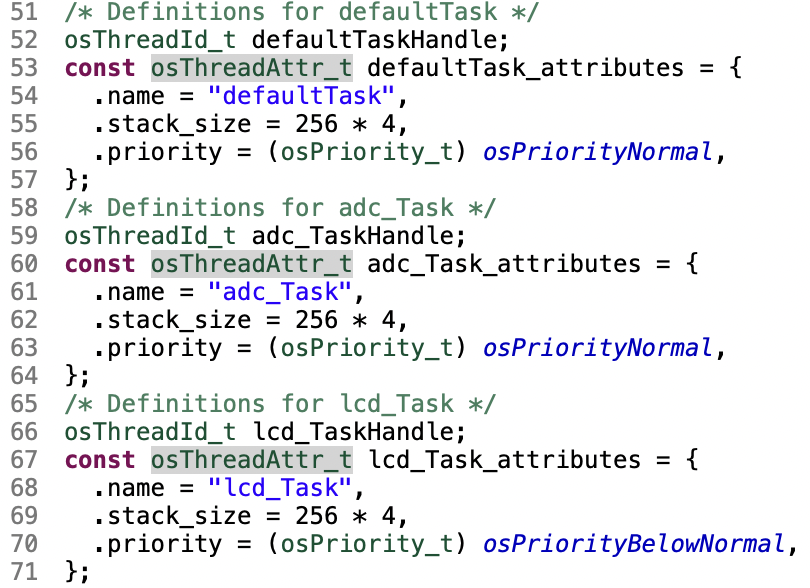
<rtosの処理>
・ADCサンプル/FFT実行タスク
表示タスクにはFETした結果が準備できたら通知(xTaskNotifyGive)、LCD表示タスク側の処理が終わったら送られる通知を待つ(ulTaskNotifyTake)
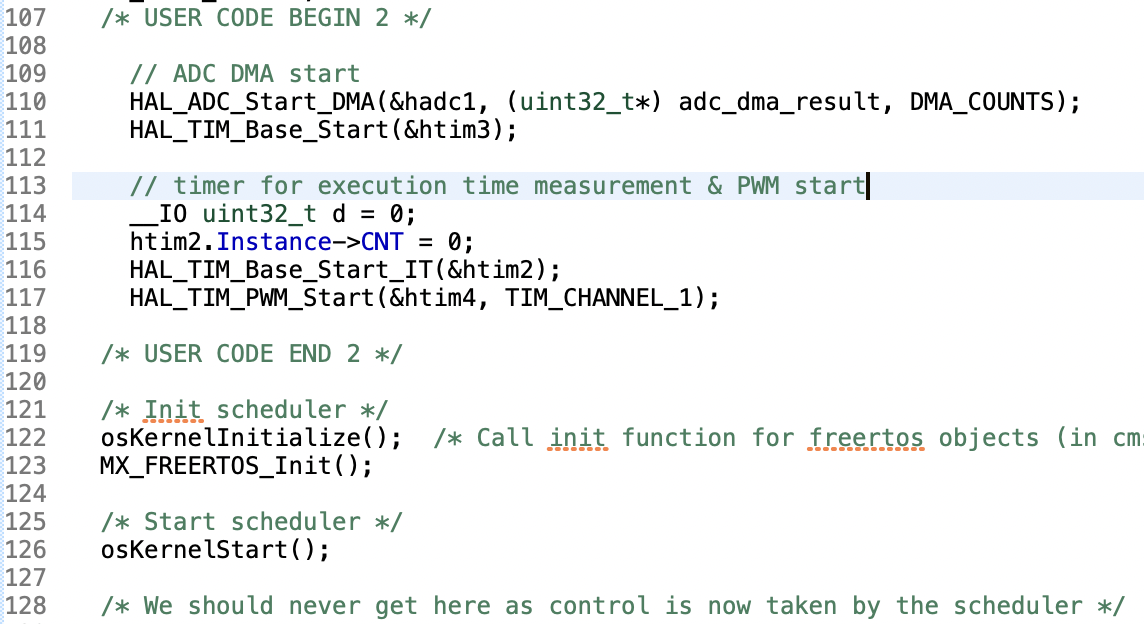
void StartTask02(void *argument) {
/* USER CODE BEGIN StartTask02 */
// ADC DMA start & Hann window coefficient calculation
Init_HannWindow(); // to prepare Hann window coefficient
Init_Iir_FFT_Instance(); // to initialize IIR filter and FFT instance
HAL_ADC_Start_DMA(&hadc1, (uint32_t*) adc_dma_buff, DMA_COUNTS);
HAL_TIM_Base_Start(&htim3);
/* Infinite loop */
for (;;) {
Adc_Process();
xTaskNotifyGive(lcd_TaskHandle); // start LCD display task
ulTaskNotifyTake(pdTRUE, portMAX_DELAY);// wait for LCD display completion
osDelay(1);
}
/* USER CODE END StartTask02 */
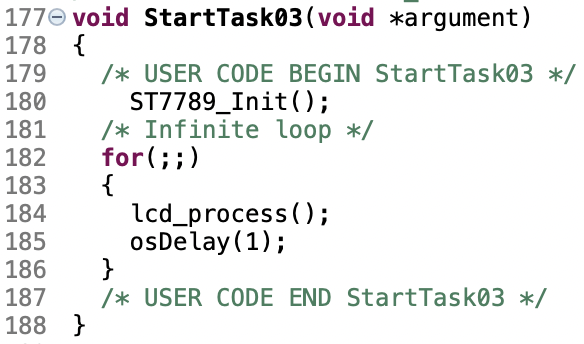
}・LCD表示タスク
void StartTask03(void *argument) {
/* USER CODE BEGIN StartTask03 */
ST7789_Init();
ST7789_SetRotation(1); // 90度回転
ST7789_Fill_Color(BLACK);
draw_fft_frame();
/* Infinite loop */
for (;;) {
ulTaskNotifyTake(pdTRUE, portMAX_DELAY); // wait for FFT data ready
Lcd_Process();
xTaskNotifyGive(adc_TaskHandle); // restart FFT task
osDelay(1);
}
/* USER CODE END StartTask03 */
}もう少し中身を吟味して次のアクション決めよう
admin