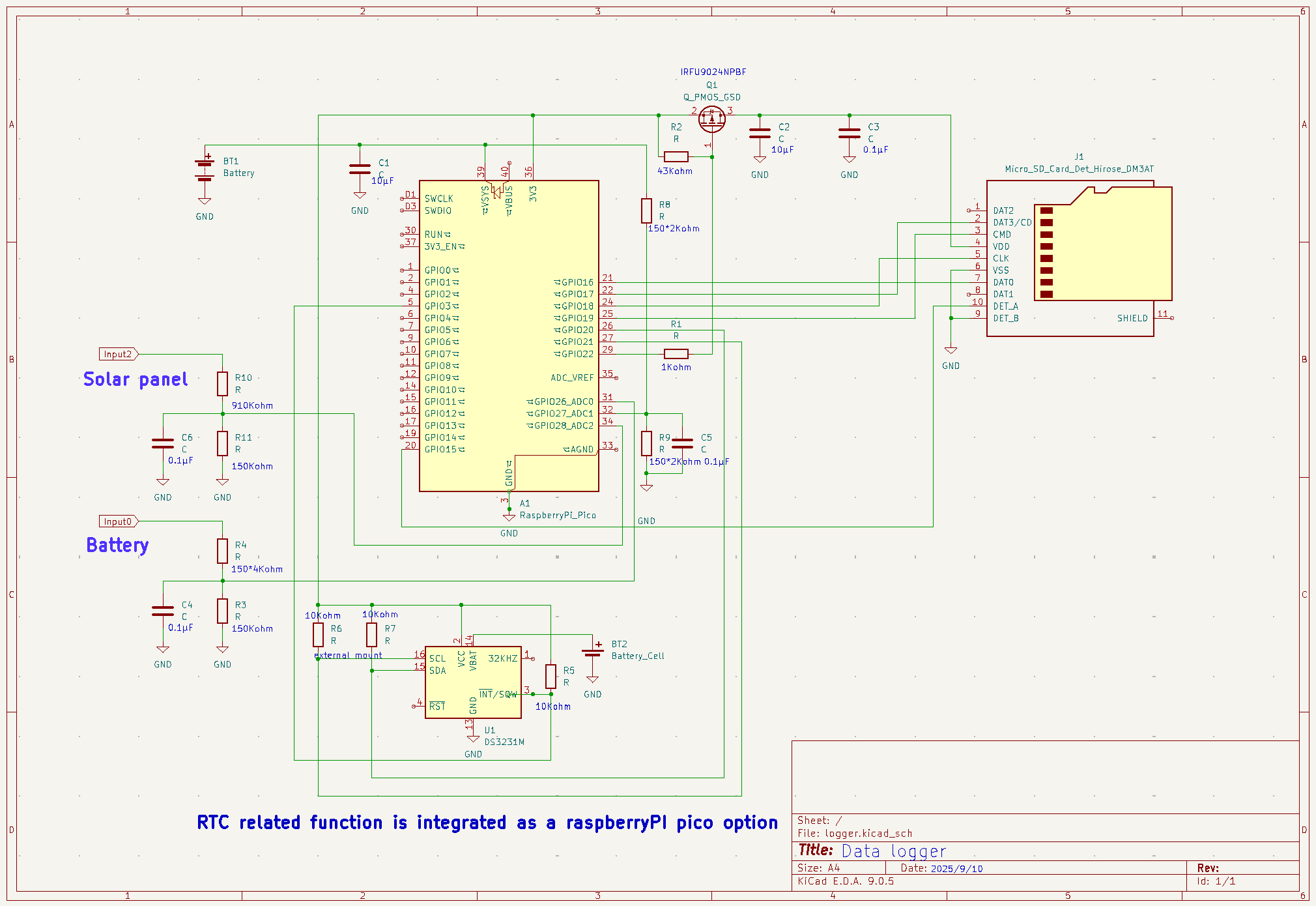
ラズピコのデータロガーの使い道で温度の記録は主要な用途かも知れないけど、屋外で使うには防水性が必要
ds18x20は1-wire製品で単品では防水性はないけれども、それを金属管に入れて防水性を確保したものが安く販売されているので購入、Amazonで3本セットで販売のもの

SHT30との測定値の差を見るために以下のコードを使用、GP2は推奨の4.7KΩでプルアップ、プルアップしなくてもそれらしい値は出てくるけど、本来的にはかりそめだと思った方が良い、特に複数本つなぐとそれなりに静電容量も増加するし
import time
import machine, onewire, ds18x20
from machine import Pin, I2C
# I2C1 (SDA=GP6, SCL=GP7)
i2c = I2C(1, scl=Pin(7), sda=Pin(6), freq=100000)
# --- SHT30 定義 ---
SHT30_ADDR = 0x44
SHT30_CMD_MEASURE = b'\x2C\x10' # set to highspeed response mode
def read_sht30():
i2c.writeto(SHT30_ADDR, SHT30_CMD_MEASURE)
time.sleep(0.008)
data = i2c.readfrom(SHT30_ADDR, 6)
temp_raw = data[0] << 8 | data[1]
hum_raw = data[3] << 8 | data[4]
temperature = -45 + (175 * temp_raw / 65535)
humidity = 100 * hum_raw / 65535
return temperature, humidity
# 1-Wire の設定(例: GP2)
dat = machine.Pin(2)
# 1-Wire バス作成
ow = onewire.OneWire(dat)
ds = ds18x20.DS18X20(ow)
# バス上のデバイスをスキャン(複数のDS18B20が繋がっている場合あり)
roms = ds.scan()
print('Found DS devices:', roms)
while True:
# 温度変換開始
ds.convert_temp()
time.sleep_ms(750) # 最大分解能(12bit)の変換待ち時間
for rom in roms:
temp = ds.read_temp(rom)
print('Device', rom, 'Temp={:.1f} C'.format(temp))
print('-' * 40)
try:
t, h = read_sht30()
print("SHT30 Temp={:.1f} C Hum={:.0f} %".format(t, h))
print("-" * 40)
except Exception as e:
print("Error:", e)
time.sleep(2)
<実行結果>
今回使用のセンサーのIDもプリントアウトするようにしてます、複数箇所の測定をする時にはセンサーで見て分かる識別手段が必要
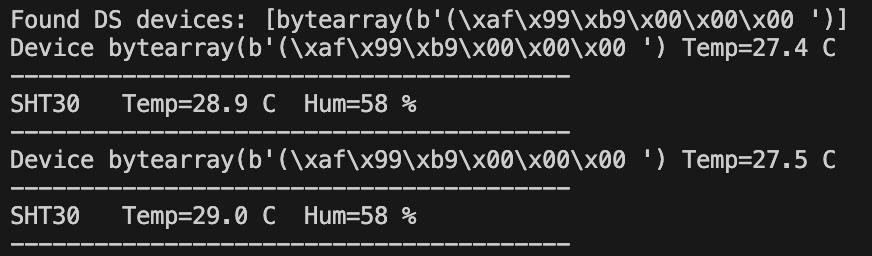
測定値で1.5℃ぐらい差があるけども、これはアプリによっては許容範囲、おそらく3本それぞれでもばらつきはあるはず
ロガー自体をケースに入れて、センサーを複数本使ってログを取るような形式になるはず
admin