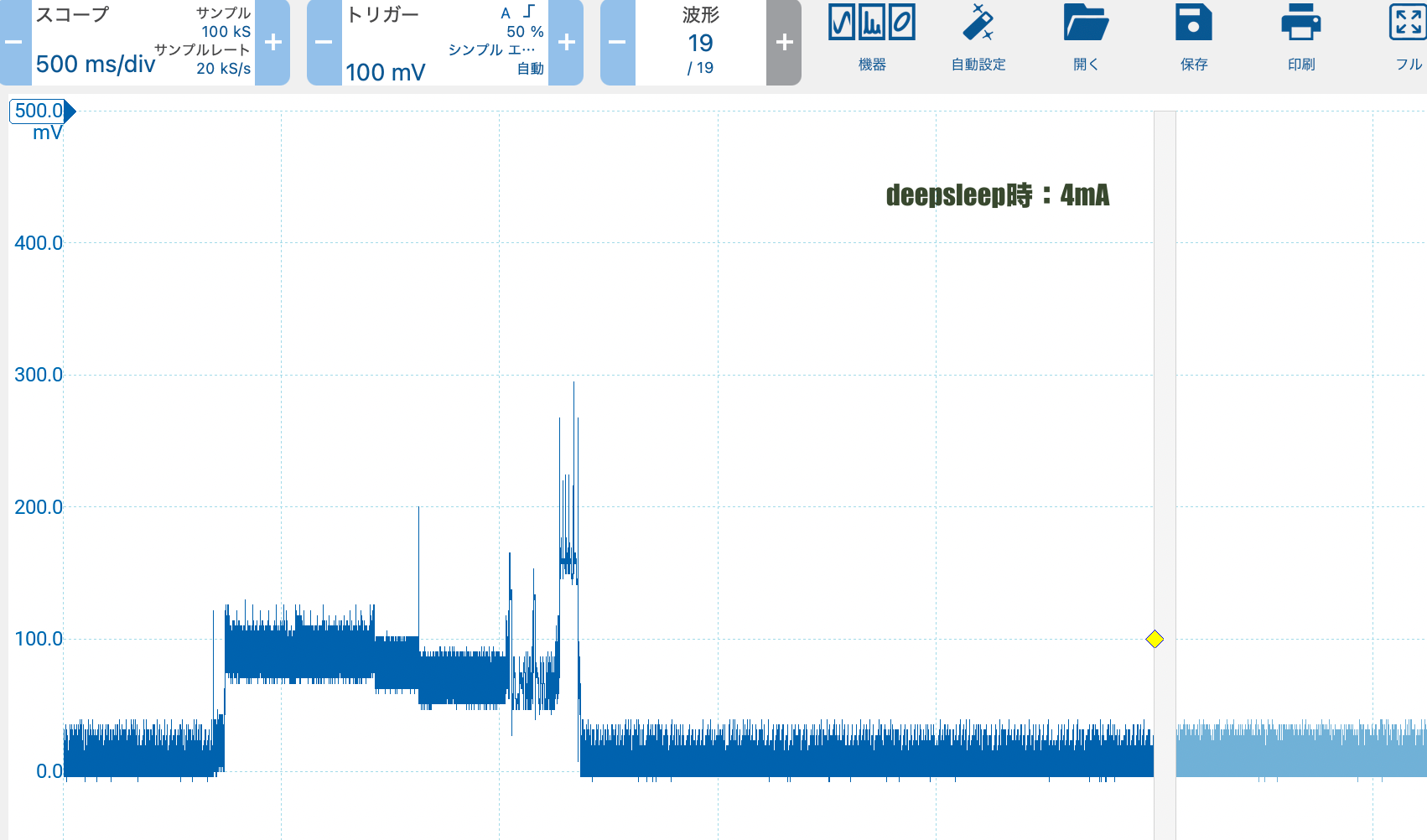
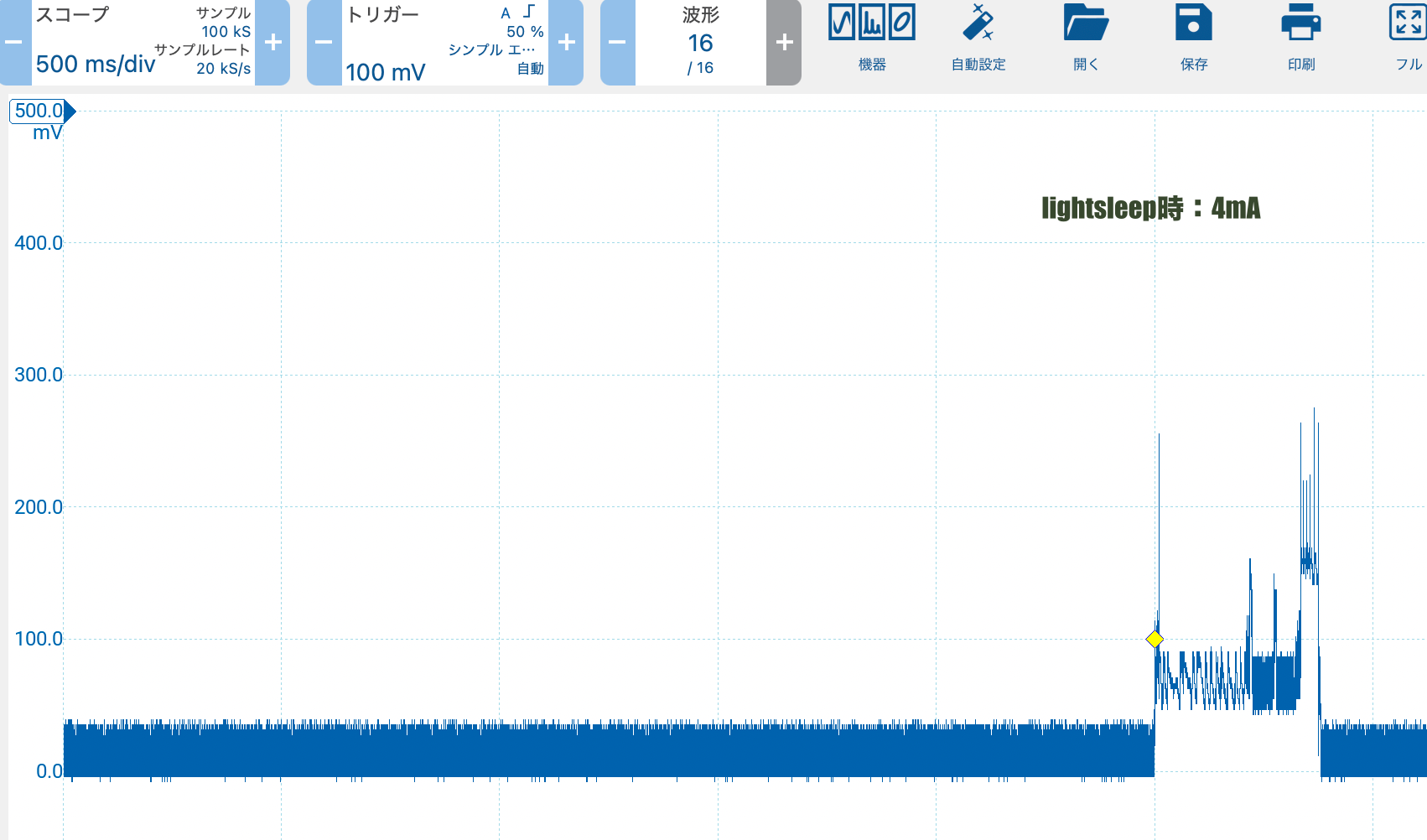
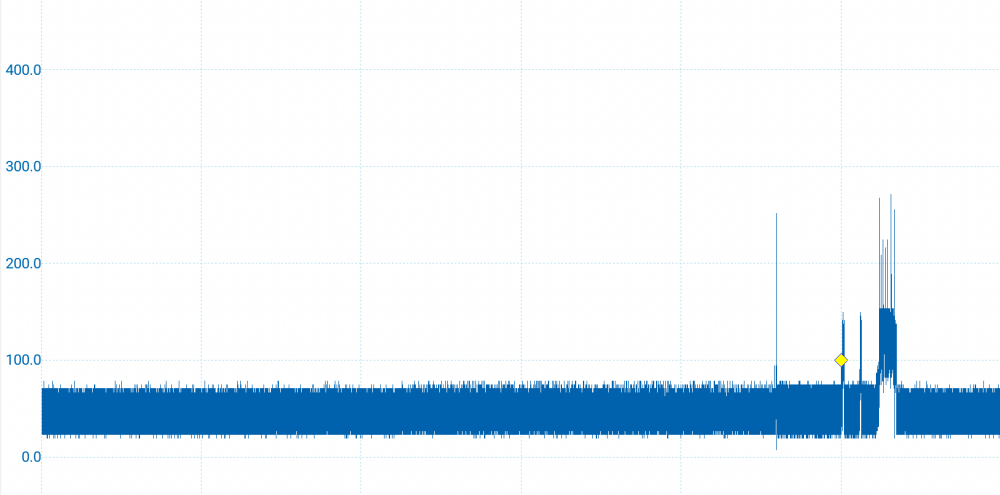
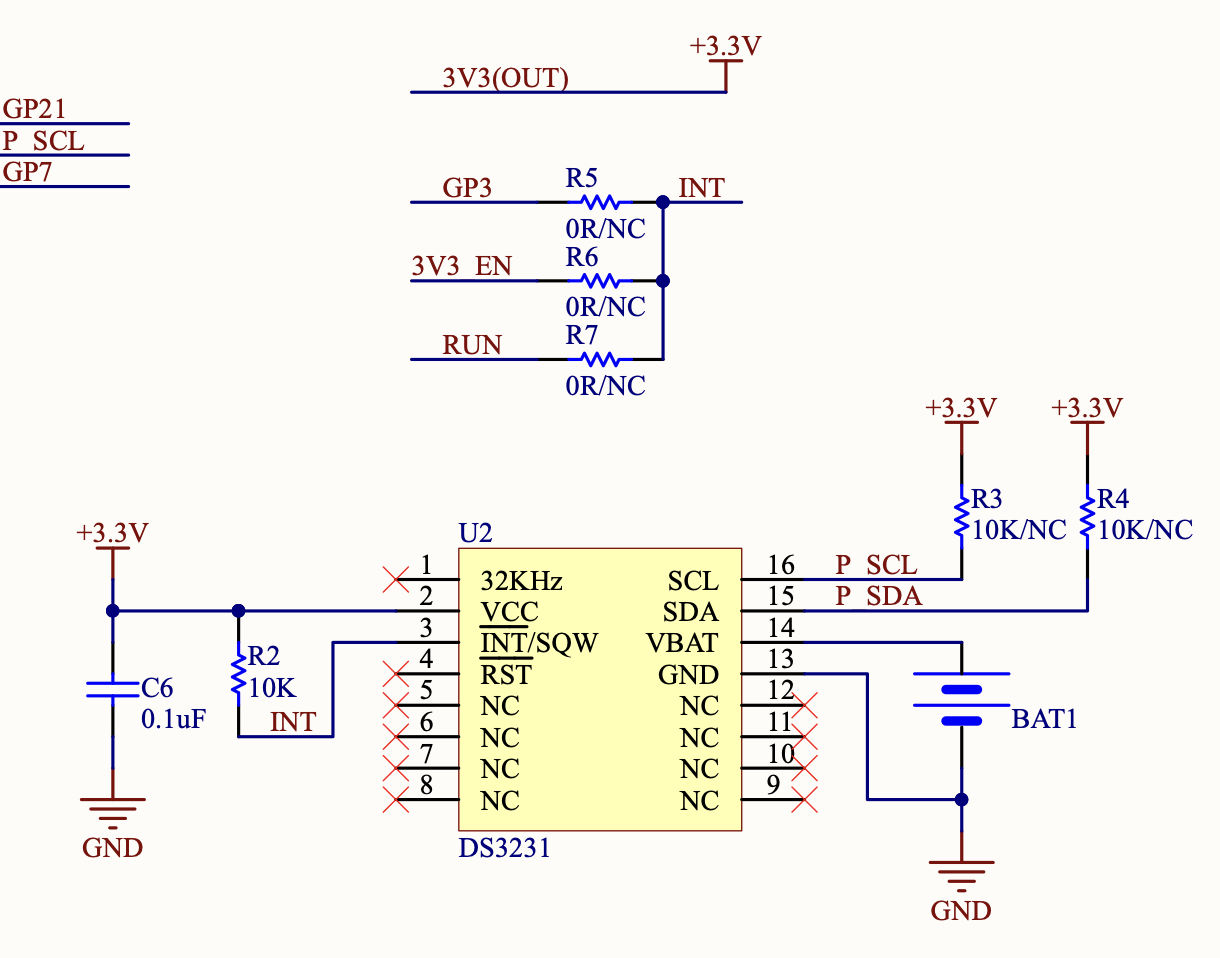
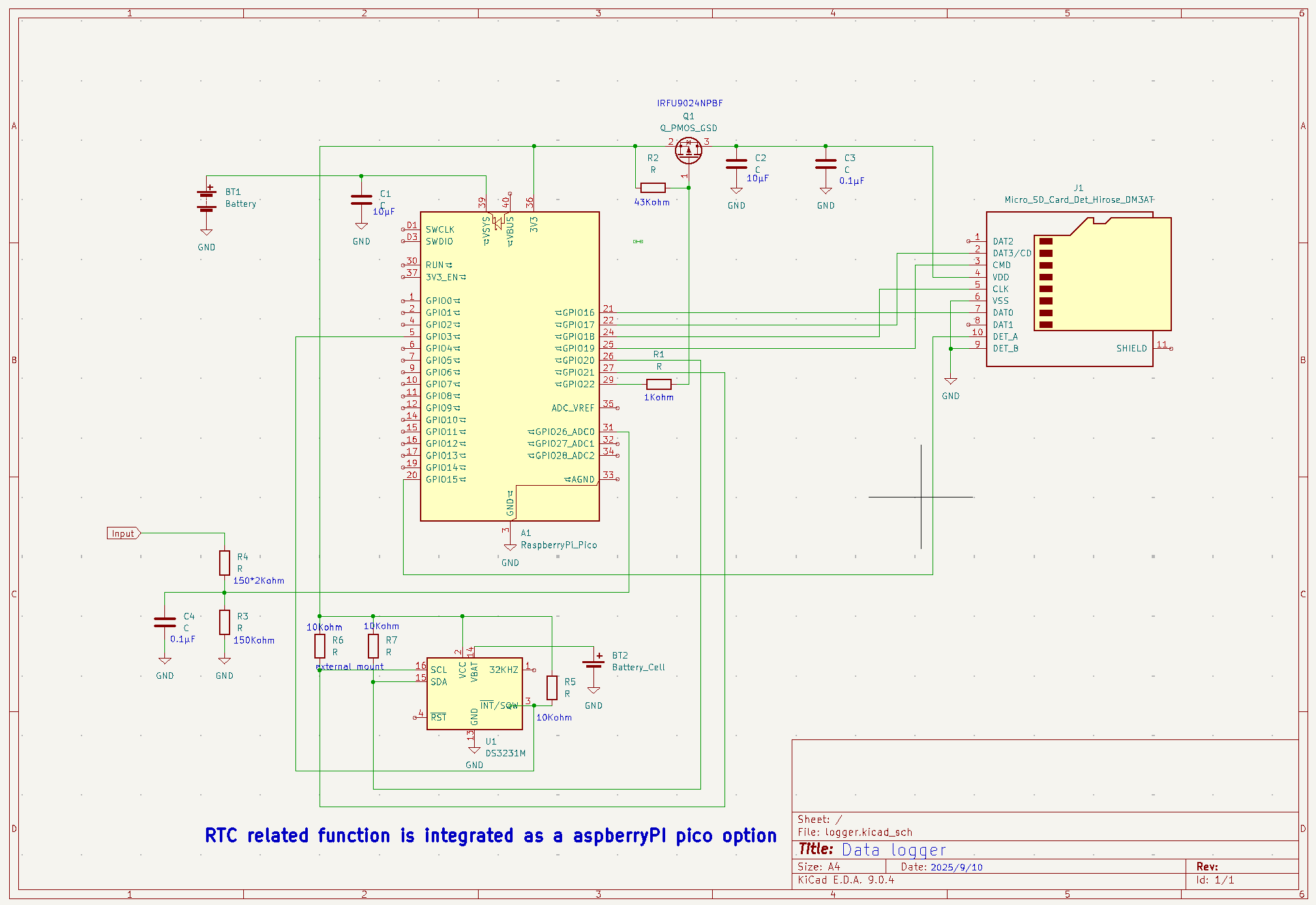
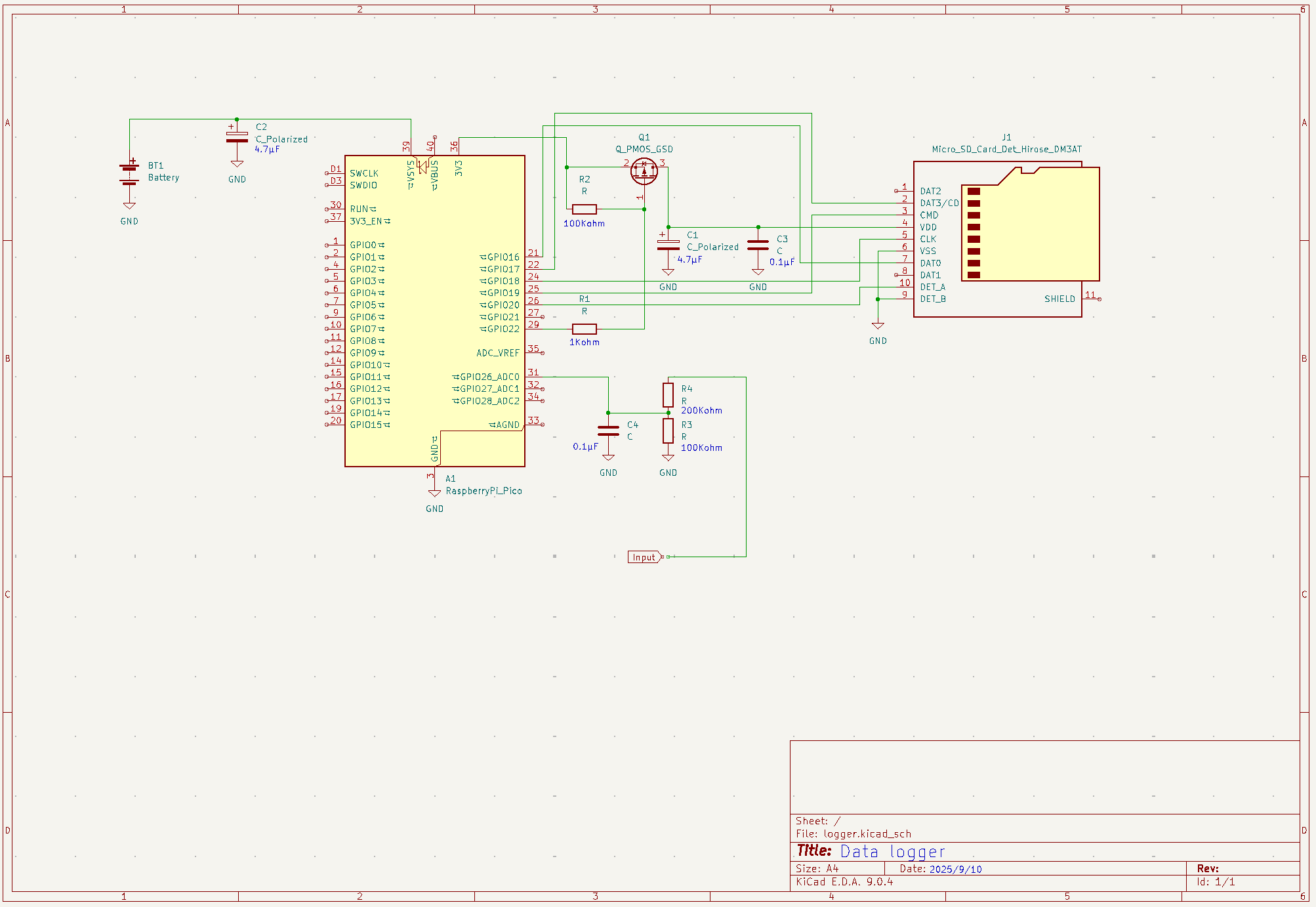
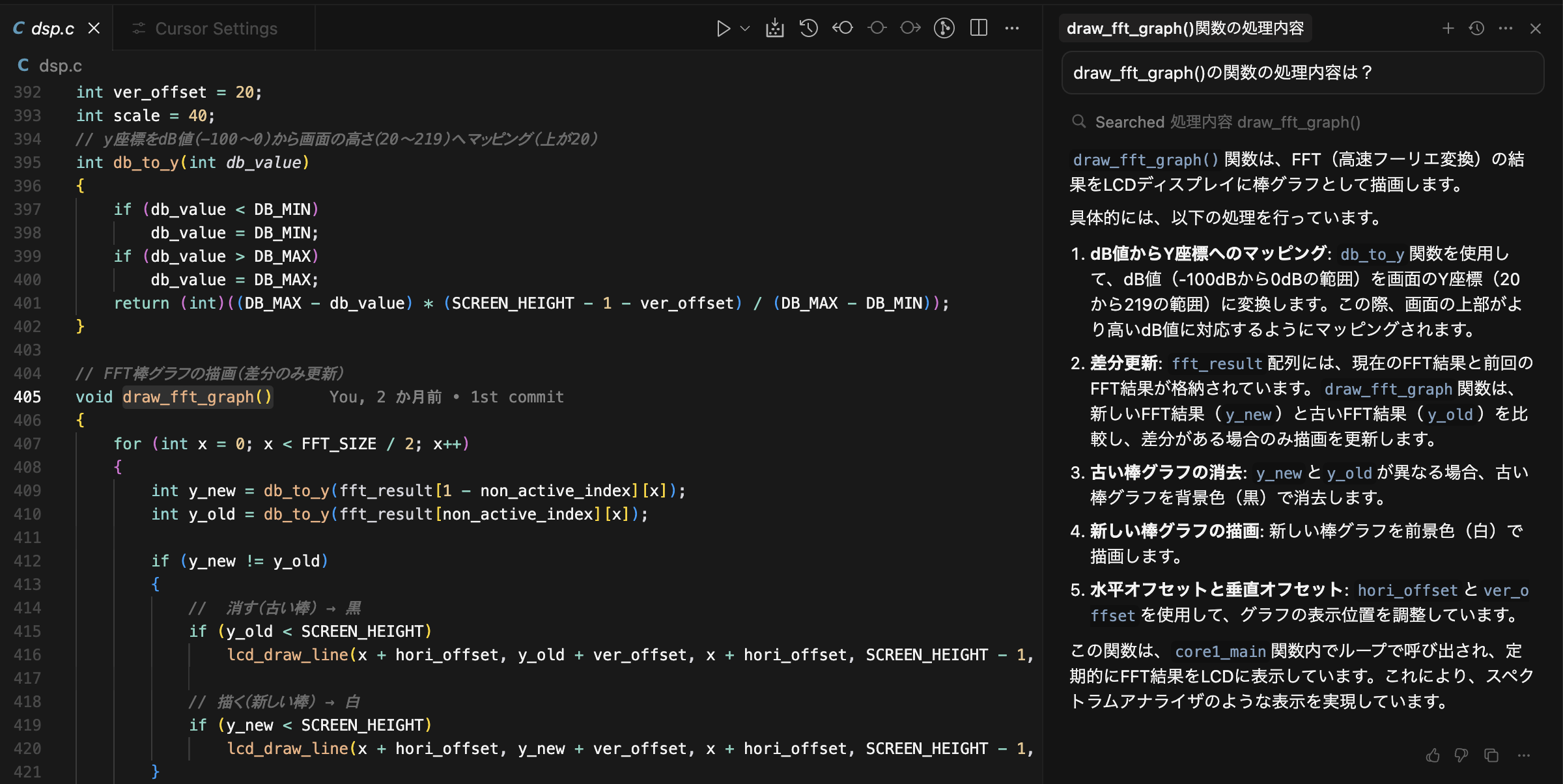
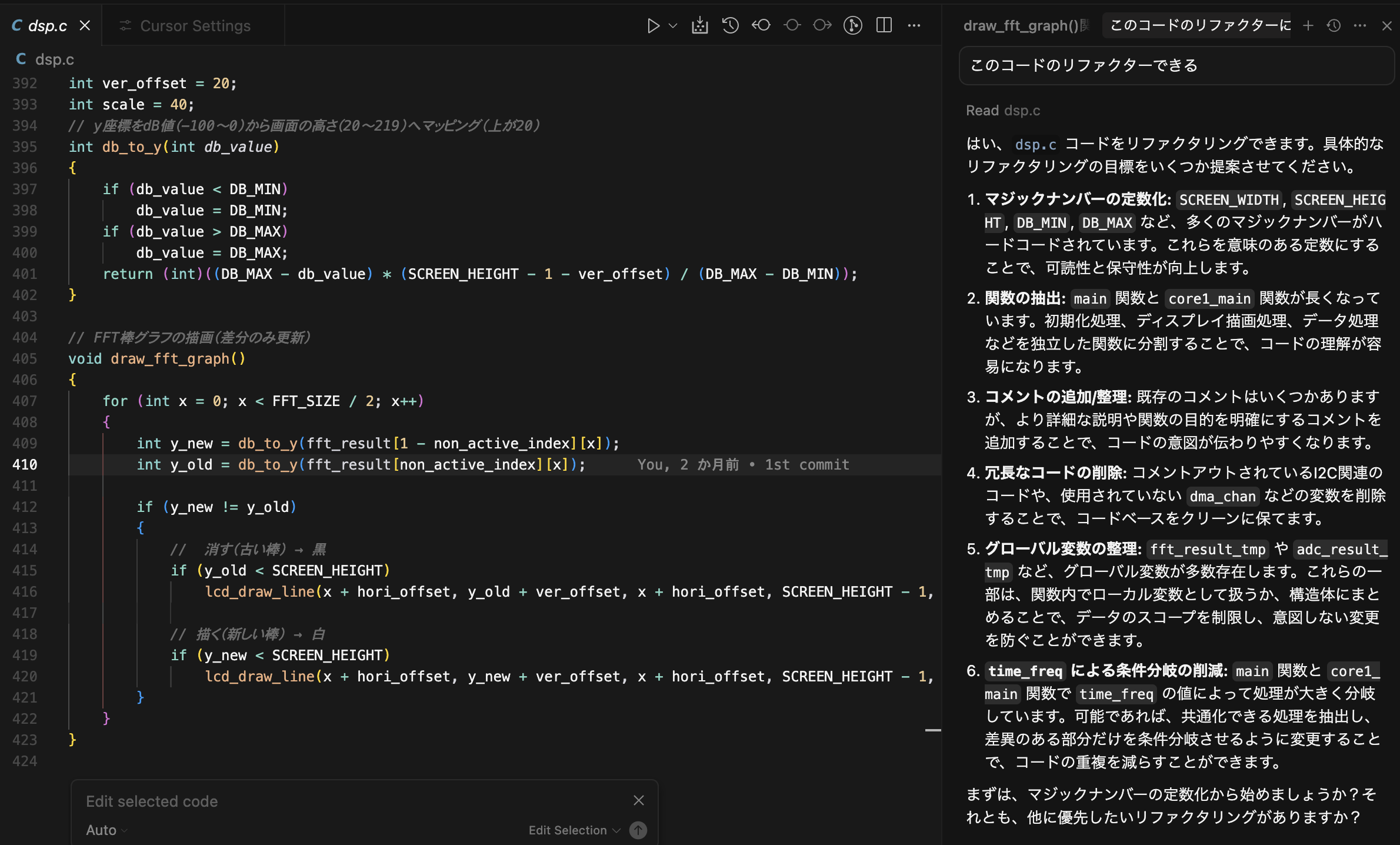
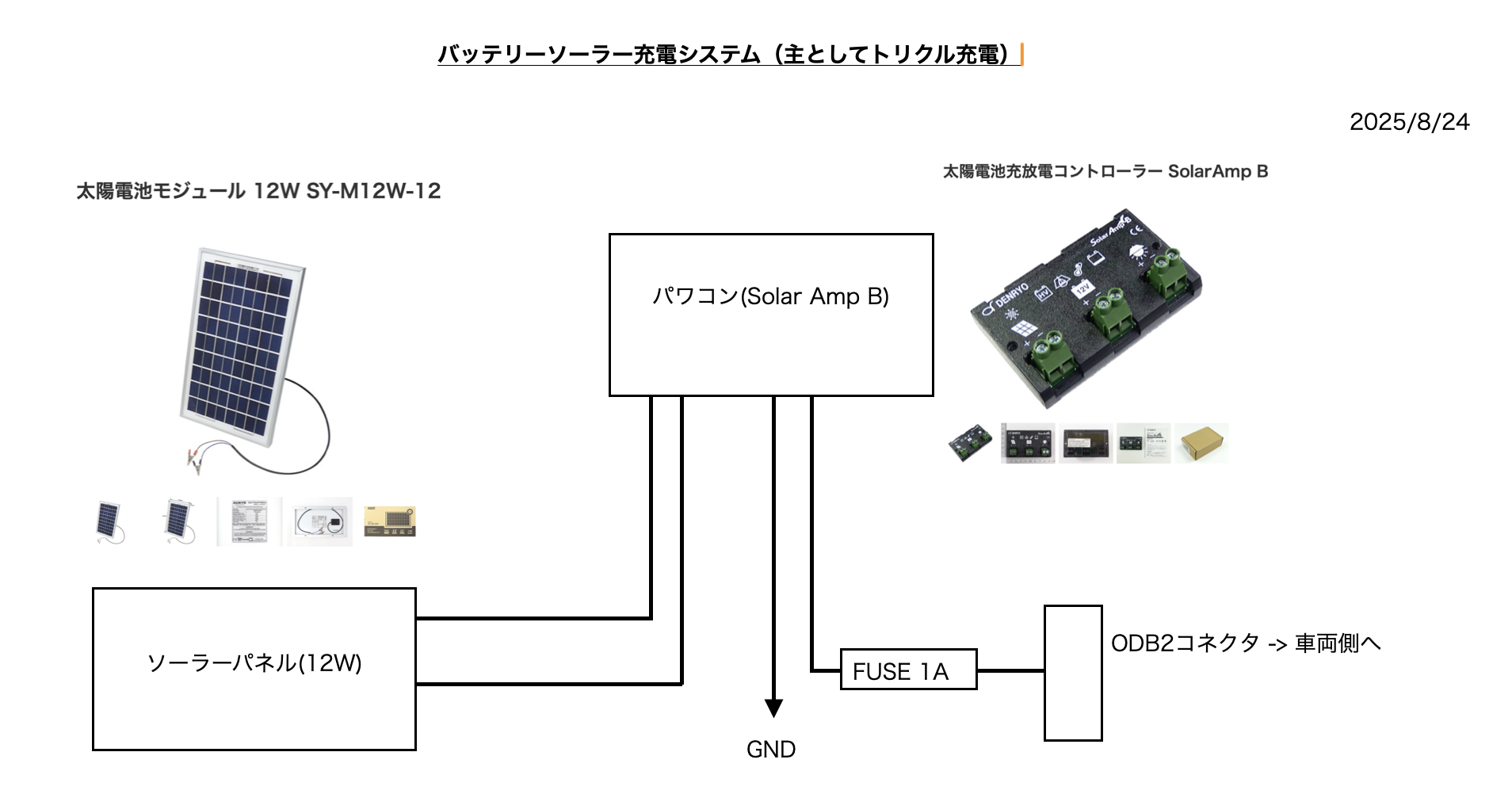
タイトル通りですが、最初の割り込みは上がってきますが、次の割り込みは上がっってこない、おそらくmicroPythonのファームの問題だろうと思うから、やはり実装はpico-sdkでやるけれどもその前に電源電流測定をしてみる
RTC関連のクラスがあるので、SD書き込み関連のクラスを追加して見通しをよくした、前回との違いはSDカードの電源供給を書き込み時点だけオンにしている点、時間待ち0.2秒は今少し短くても良さそうだ、システムはアクティブなので信号線からの回り込みでSDカードの電源線の電圧は2V以上はあるからSDへのダメージ対策として、SDへの書き込み終わったらSPIを無効化後に入力High-Zにして回り込みをソフト的に抑制するようにした
#!/usr/bin/python
# -*- coding: utf-8 -*-
from machine import Pin, I2C, ADC, SPI
import time
import binascii
import machine, sdcard, uos
I2C_PORT = 0
I2C_SDA = 20
I2C_SCL = 21
SD_ON = 22
ALARM_PIN = 3
alarm_triggered = False
adc0 = ADC(Pin(26)) # ADC0
adc1 = ADC(Pin(27)) # ADC1
# -----------------------------
# RTC ds3231 class
# -----------------------------
class ds3231():
w = ["Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday"];
address = 0x68
start_reg = 0x00
alarm1_reg = 0x07
control_reg = 0x0e
status_reg = 0x0f
def __init__(self,i2c_port,i2c_scl,i2c_sda):
self.bus = I2C(i2c_port,scl=Pin(i2c_scl),sda=Pin(i2c_sda))
self.alarm_pin = Pin(ALARM_PIN, Pin.IN, Pin.PULL_UP)
self.alarm_pin.irq(handler=self.alarm_irq_handler, trigger=Pin.IRQ_FALLING)
def set_time(self,new_time):
hour = new_time[0] + new_time[1]
minute = new_time[3] + new_time[4]
second = new_time[6] + new_time[7]
week = "0" + str(self.w.index(new_time.split(",",2)[1])+1)
year = new_time.split(",",2)[2][2] + new_time.split(",",2)[2][3]
month = new_time.split(",",2)[2][5] + new_time.split(",",2)[2][6]
day = new_time.split(",",2)[2][8] + new_time.split(",",2)[2][9]
now_time = binascii.unhexlify((second + " " + minute + " " + hour + " " + week + " " + day + " " + month + " " + year).replace(' ',''))
self.bus.writeto_mem(int(self.address),int(self.start_reg),now_time)
def alarm_irq_handler(self, pin):
global alarm_triggered
alarm_triggered = True
def set_alarm_time(self, alarm_time):
self.alarm_pin = Pin(ALARM_PIN, Pin.IN, Pin.PULL_UP)
self.alarm_pin.irq(handler=self.alarm_irq_handler, trigger=Pin.IRQ_FALLING)
# ステータスフラグクリア
status = rtc.bus.readfrom_mem(rtc.address, rtc.status_reg, 1)
rtc.bus.writeto_mem(rtc.address, rtc.status_reg, bytes([status[0] & 0xFE]))
# コントロールレジスタ設定
self.bus.writeto_mem(self.address, self.control_reg, b'\x07')
# アラーム時刻設定
hour = alarm_time[0] + alarm_time[1]
minute = alarm_time[3] + alarm_time[4]
second = alarm_time[6] + alarm_time[7]
date = alarm_time.split(",", 2)[2][8] + alarm_time.split(",", 2)[2][9]
now_time = binascii.unhexlify((second + minute + hour + date).replace(' ', ''))
self.bus.writeto_mem(self.address, self.alarm1_reg, now_time)
def get_date(self):
t = self.bus.readfrom_mem(self.address, self.start_reg, 7)
year = 2000 + bcd2dec(t[6])
month = bcd2dec(t[5])
day = bcd2dec(t[4])
return year, month, day
def bcd2dec(bcd):
return ((bcd >> 4) * 10) + (bcd & 0x0F)
# -----------------------------
# SDLoggerVFS class (SPI + Hi-Z安全化)
# -----------------------------
class SDLoggerVFS:
def __init__(self, spi_id, cs_pin, power_pin):
self.spi_id = spi_id
self.cs_pin = cs_pin
self.power_pin = Pin(power_pin, Pin.OUT)
self.mount_point = '/sd'
self.spi = None
# SPIピン番号
self.SCK_PIN = 18
self.MOSI_PIN = 17
self.MISO_PIN = 16
def power_on(self):
self.power_pin.value(0)
time.sleep(0.2)
def power_off(self):
self.power_pin.value(1)
def spi_init(self):
self.spi = SPI(self.spi_id, baudrate=1_000_000, polarity=0, phase=0)
def spi_deinit_and_hiz(self):
if self.spi:
self.spi.deinit()
self.spi = None
# ピンをHi-Z入力に戻してpull-down
Pin(self.MOSI_PIN, Pin.IN, Pin.PULL_DOWN)
Pin(self.MISO_PIN, Pin.IN, Pin.PULL_DOWN)
Pin(self.SCK_PIN, Pin.IN, Pin.PULL_DOWN)
def write(self, rtc, value1, value2):
# SDカード電源ON
self.power_on()
# SPI初期化
self.spi_init()
# SDCardライブラリ初期化
sd = sdcard.SDCard(self.spi, Pin(self.cs_pin))
# マウント
uos.mount(sd, self.mount_point)
# ファイル書き込み
year, month, day = rtc.get_date()
filename = f"{self.mount_point}/{year:04d}-{month:02d}-{day:02d}.txt"
with open(filename, 'a') as f:
f.write(f"{value1},{value2}\n")
# アンマウント
uos.umount(self.mount_point)
# SPI停止 + Hi-Z化
self.spi_deinit_and_hiz()
# SDカード電源OFF
self.power_off()
# -----------------------------
# RTC時間加算用
# -----------------------------
def add_time_period_to_rtc_time(rtc):
t = rtc.bus.readfrom_mem(rtc.address, rtc.start_reg, 7)
year = 2000 + bcd2dec(t[6])
month = bcd2dec(t[5] & 0x1F)
day = bcd2dec(t[4] & 0x3F)
hour = bcd2dec(t[2] & 0x3F)
minute = bcd2dec(t[1] & 0x7F)
second = bcd2dec(t[0] & 0x7F)
weekday = t[3] & 0x07
def is_leap(year):
return (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0)
def days_in_month(y, m):
mdays = [31, 29 if is_leap(y) else 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
return mdays[m-1]
second += 10
if second >= 60:
second -= 60
minute += 1
if minute >= 60:
minute = 0
hour += 1
if hour >= 24:
hour = 0
day += 1
weekday = weekday + 1 if weekday < 7 else 1 if day > days_in_month(year, month):
day = 1
month += 1
if month > 12:
month = 1
year += 1
w = ["Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday"]
weekday_str = w[weekday-1]
alarm_time_str = "{:02d}:{:02d}:{:02d},{},{:04d}-{:02d}-{:02d}".format(
hour, minute, second, weekday_str, year, month, day)
return alarm_time_str
def set_alarm():
alarm_time_later = add_time_period_to_rtc_time(rtc)
print("Alarm time 10 sec later:", alarm_time_later)
rtc.set_alarm_time(alarm_time_later)
rtc.alarm_pin = Pin(ALARM_PIN, Pin.IN, Pin.PULL_UP)
def clear_alarm_flag():
status = rtc.bus.readfrom_mem(rtc.address, rtc.status_reg, 1)
rtc.bus.writeto_mem(rtc.address, rtc.status_reg, bytes([status[0] & 0xFE]))
# -----------------------------
# main
# -----------------------------
if __name__ == '__main__':
rtc = ds3231(I2C_PORT,I2C_SCL,I2C_SDA)
set_alarm()
logger = SDLoggerVFS(0, 17, SD_ON)
value1 = round((adc0.read_u16() >> 4) * 3.3 * 3 / 4096, 2)
value2 = round((adc1.read_u16() >> 4) * 3.3 * 2 / 4096, 2)
print(value1, value2)
logger.write(rtc, value1, value2)
try:
while True:
if alarm_triggered:
alarm_triggered = False
clear_alarm_flag()
time.sleep_ms(5)
set_alarm()
value1 = round((adc0.read_u16() >> 4) * 3.3 * 3 / 4096, 2)
value2 = round((adc1.read_u16() >> 4) * 3.3 * 2 / 4096, 2)
print(value1, value2)
if value2 > 1.8:
logger.write(rtc, value1, value2)
time.sleep(10)
except KeyboardInterrupt:
print("terminated")