ラズパイzeroは段違いに遅いことはわかっていたけれども、どれだけ遅いのかをみてみた、ソースコードは共通ですがzeroはシングルコアなのでマルチスレッドの数値はなし
コンパイルもzeroでは実質的にはできないからMac上でクロスでバイナリ作成してます
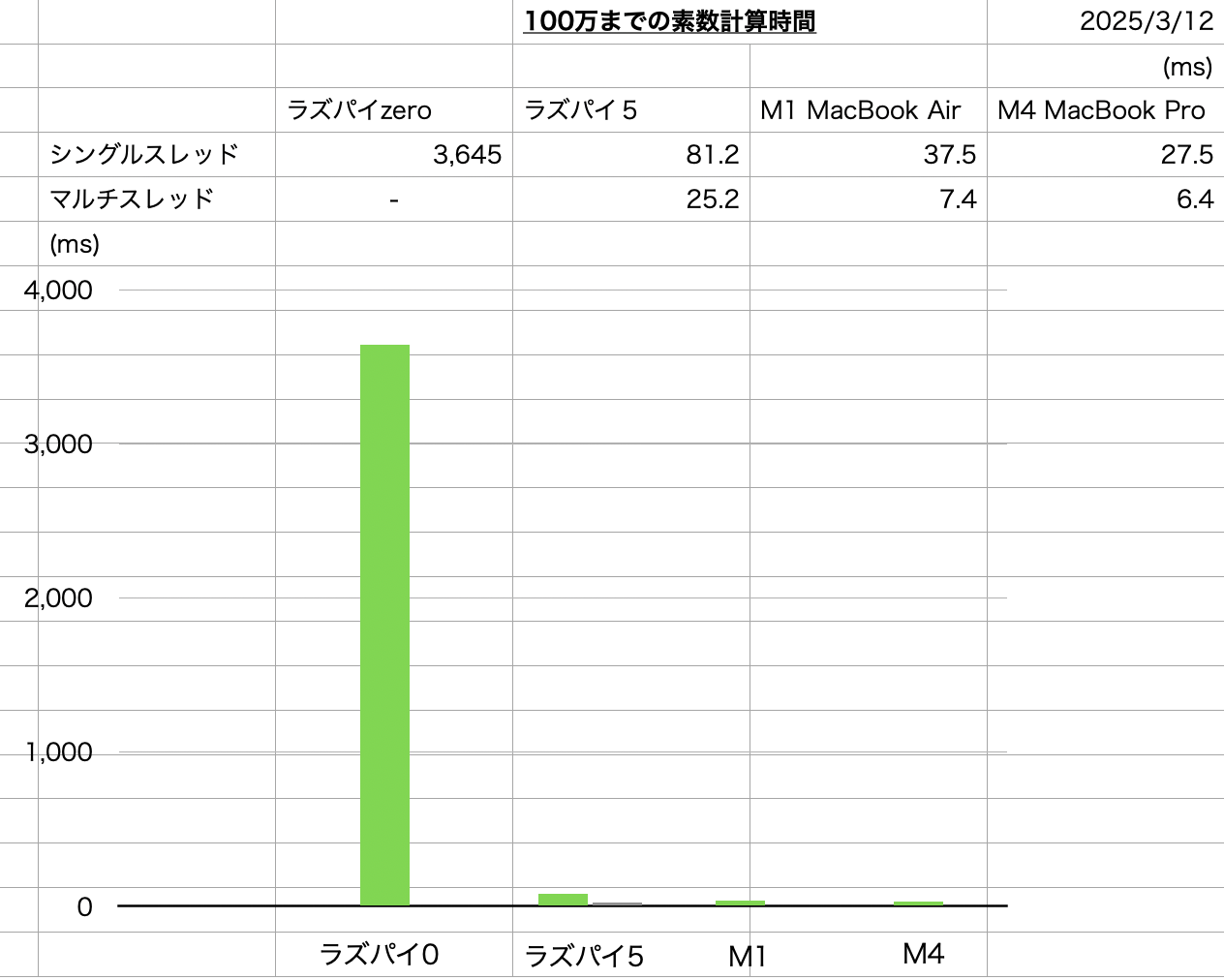
比較してみると、他に比べて絶望的に遅いことがわかります、まあアプリケーションによって使い分けるわけではありますが
admin

la vie libre
ラズパイzeroは段違いに遅いことはわかっていたけれども、どれだけ遅いのかをみてみた、ソースコードは共通ですがzeroはシングルコアなのでマルチスレッドの数値はなし
コンパイルもzeroでは実質的にはできないからMac上でクロスでバイナリ作成してます
比較してみると、他に比べて絶望的に遅いことがわかります、まあアプリケーションによって使い分けるわけではありますが
admin
Apple Siliconとの比較でラズパイ5で実行時間も測定してみた、Apple Siliconの数値は以下のリンクから
https://isehara-3lv.sakura.ne.jp/blog/2025/03/10/m1-vs-m4の性能比較(非常に限定的な場合で)/
<ラズパイ5の実行結果>
ラズパイ5のRustでの実行速度
<シングルスレッド>
pi@rasp5:~/rust/prime_single_thread/src $ cargo run --release
Finished `release` profile [optimized] target(s) in 0.00s
Running `/home/pi/rust/prime_single_thread/target/release/prime_single_thread`
2から1000000までの素数:
Elapsed time: 81.208438ms
number of primes: 78498
<マルチスレッド>
pi@rasp5:~/rust/prime/src $ cargo run --release
Finished `release` profile [optimized] target(s) in 0.01s
Running `/home/pi/rust/prime/target/release/prime`
2から1000000までの素数:
Elapsed time: 25.209907ms
number of primes: 78498<Apple siliconとの比較>
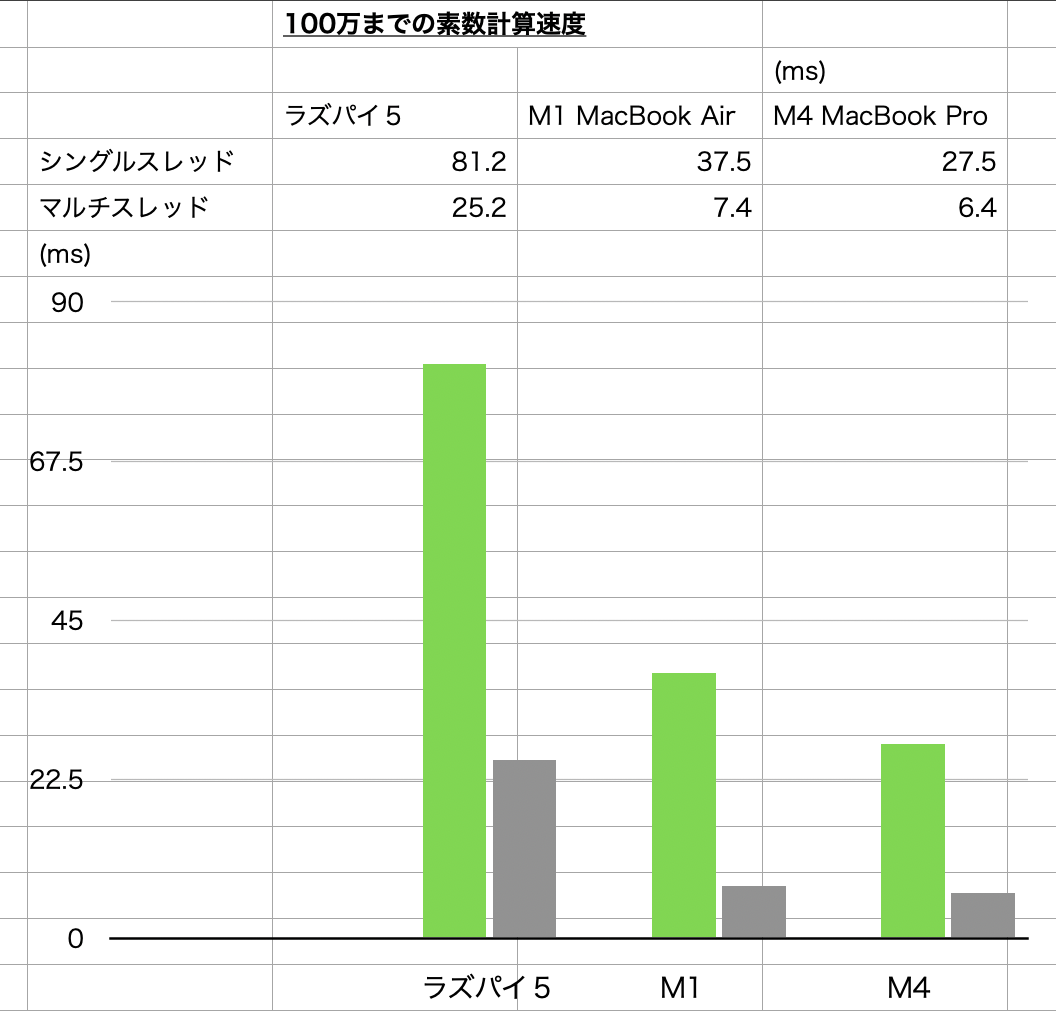
予想外にラズパイ5が早いというべきか、Mxが遅いというべきか、概ねM1 Macとラズパイzeroだと概ね速度差は60倍ぐらいあったのが、ラズパイ5だとその差は3倍ぐらい、ということはラズパイzeroと5で実行速度は20倍ぐらいの差があるということになるから、ちょうど2018年ごろのMacBook Air(Intel CPU)の速度ぐらいは出ているということになるだろう、体感速度というのはCPU速度だけではなくファイルアクセスも重要だからSDカードで動かしているラズパイ5はかなりハンディはあるだろう
ラズパイzeroでRustやGolangのコンパイルは実用的な速度で実行できないけど、ラズパイ5なら問題なくできるから、言い換えれば一桁以上の性能差があるということだから、体感というのは概ね当たっているようだ
P.S. 2025/3/12
ラズパイzeroの実行時間は次の記事で追加、予想のさらに下でした
admin
視覚相当機能はラズパイ5の標準カメラで実現しますが、ロボットなので目玉風に格納したい
目玉の中心部にカメラ、カメラを覆うような形でサーボモーターで瞼を動かしてみる
<瞼側>

<眼球側>
サーボモーターを取り付け部分はそのままだと造形できないので、仮にサポートを立てて、後でハンダゴテで溶かしてニッパーで切り落とし、最初からニッパーだとストレスで割れます

<カメラ取り付け>

<カメラの外観>

<可動部分>

<動作の動画>
カメラからの画像をどう扱うかはこれから、YOLOとか有力だと思うけど
<サーボモーター駆動のコード>
PWM機能はgpiodにないのでソフトでPWM作成
import gpiod
import time
CHIP = 'gpiochip4' # Raspberry Pi 5では'gpiochip4'を使用
PIN = 18
chip = gpiod.Chip(CHIP)
line = chip.get_line(PIN)
line.request(consumer="Servo", type=gpiod.LINE_REQ_DIR_OUT)
def set_servo_angle(angle):
duty_cycle = (angle / 18) + 2.5
pulse_width = duty_cycle / 100 * 20000 # 20ms周期
line.set_value(1)
time.sleep(pulse_width / 1000000)
line.set_value(0)
time.sleep((20000 - pulse_width) / 1000000)
try:
while True:
for angle in range(80,141, 5):
for _ in range(10): # 各角度でn回パルスを送信
set_servo_angle(angle)
time.sleep(0.1)
except KeyboardInterrupt:
pass
finally:
line.release()
admin
タイトル通りですが、やることは二つ
一つ目はLocalを日本に設定して5Gが使えるようにすること
二つ目は複数のSSIDを使っている時に(今回はnaとn接続の場合には)acのSSIDの優先順位を高く設定する
この二つですが、ロケール設定はraspy-configで、優先順位指定は最近のラズパイOSでは設定ファイル編集ではなく、nmcli(おそらくnatwork manager by command line interfaceの略)を使うようです
以下、二つのSSIDの場合の設定例です
設定(数字が大きい方を優先する、デフォルトは0らしい)
$ sudo nmcli connection modify "preconfigured" connection.autoconnect-priority 100
確認方法
$ nmcli connection show "preconfigured" | grep connection.autoconnect-priority
connection.autoconnect-priority: 100
$ nmcli connection show "他のssid” | grep connection.autoconnect-priority
connection.autoconnect-priority: 0この場合、デフォルト設定の方がac接続なのでそこの優先順位を上げました、これで設定を有効(リブートあるいはnmcliで指定)すれば大丈夫です
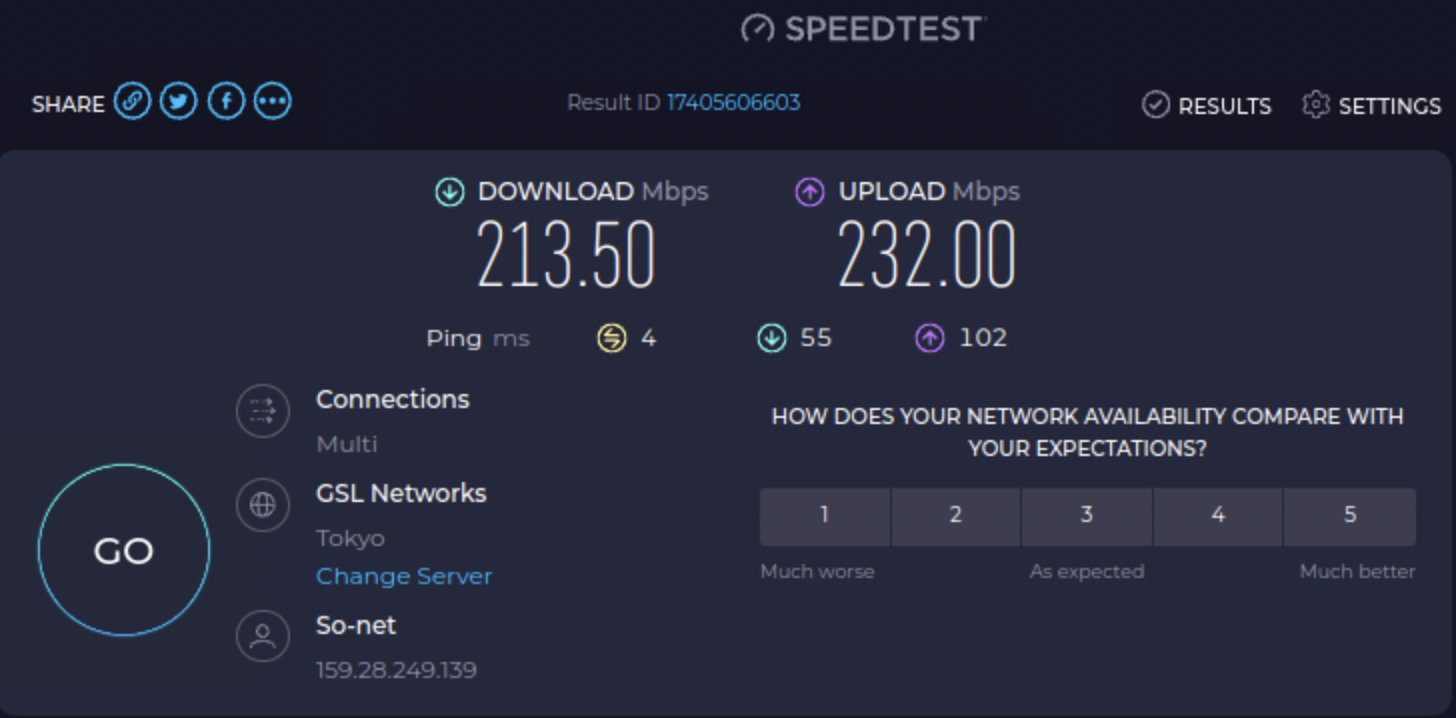
ブラウザからの速度確認で、n接続では30Mbps程度でしたが、この程度の速度になりました、ac接続としてはそれほど高速でもないですが、相対的にはかなり速くはなってます
admin
ラズパイ5で大きなハードウェア変更があり、結果としてgpioを扱うライブラリも変更があったようです、一番大きな変更はcやPythonでgpio扱う時にはroot権限でないと動作しないということかもしれません

プロービングしやすいgpioの21ピンを対象にして、動かしてみました
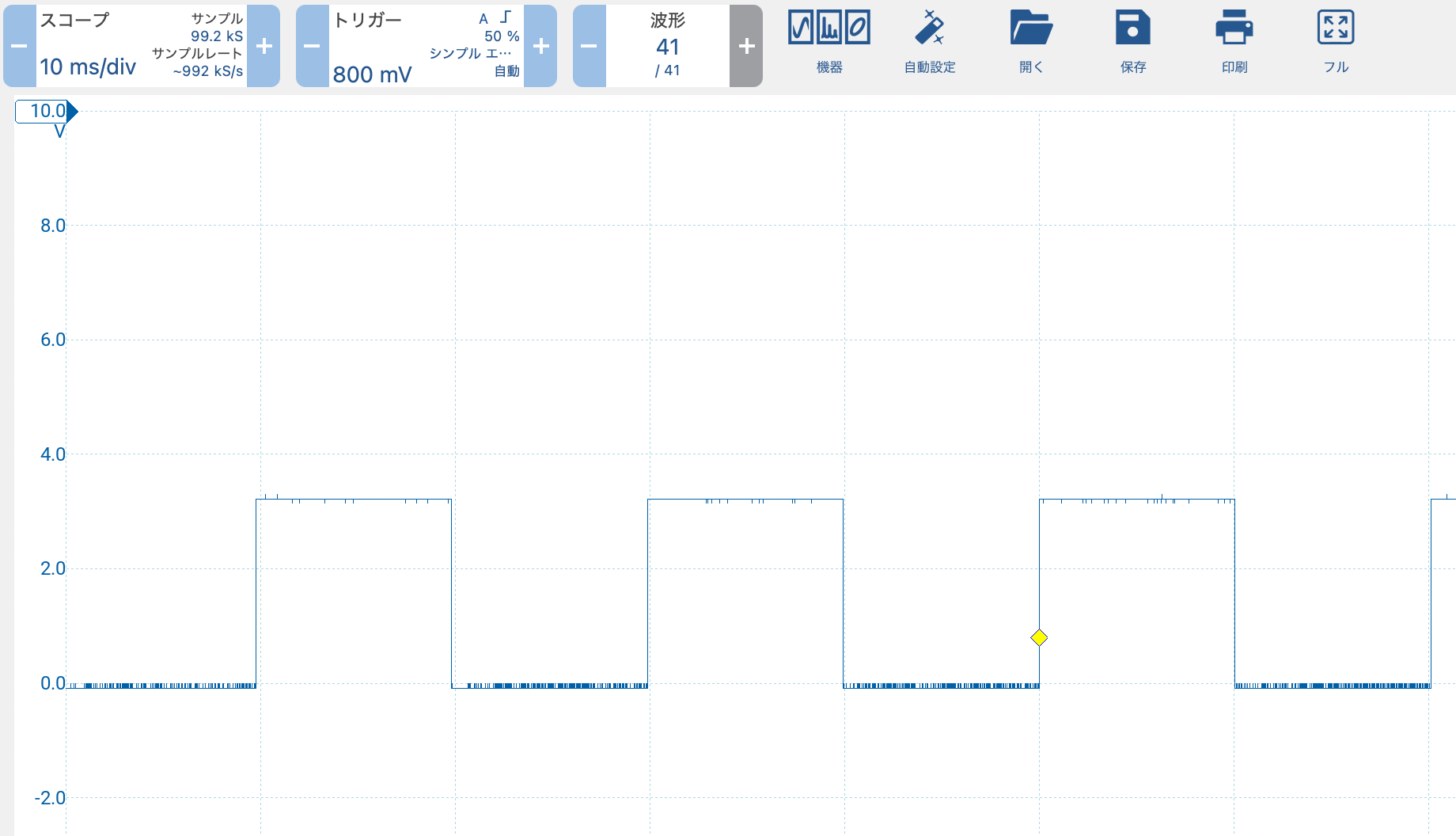
これはPythonのコード、10ms毎にステートを0,1 繰り返しているだけ
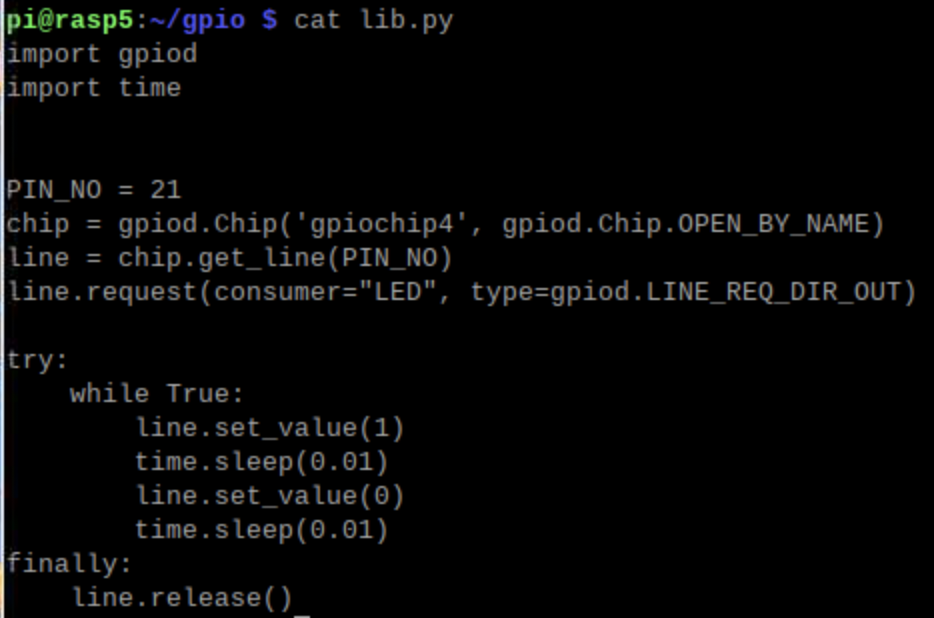
こんな当たり前の波形
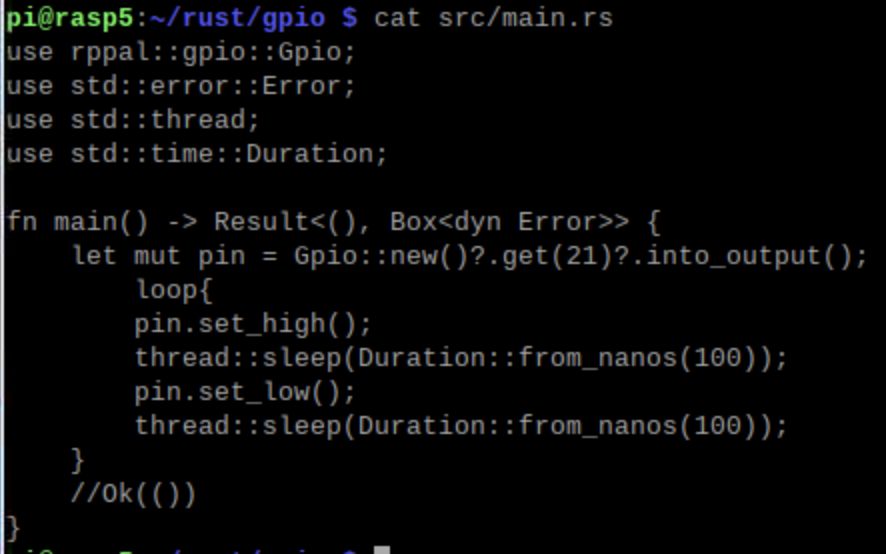
次にRustでもやってみた、以下がコードですが終了しないので最後のok(())はコメントアウト
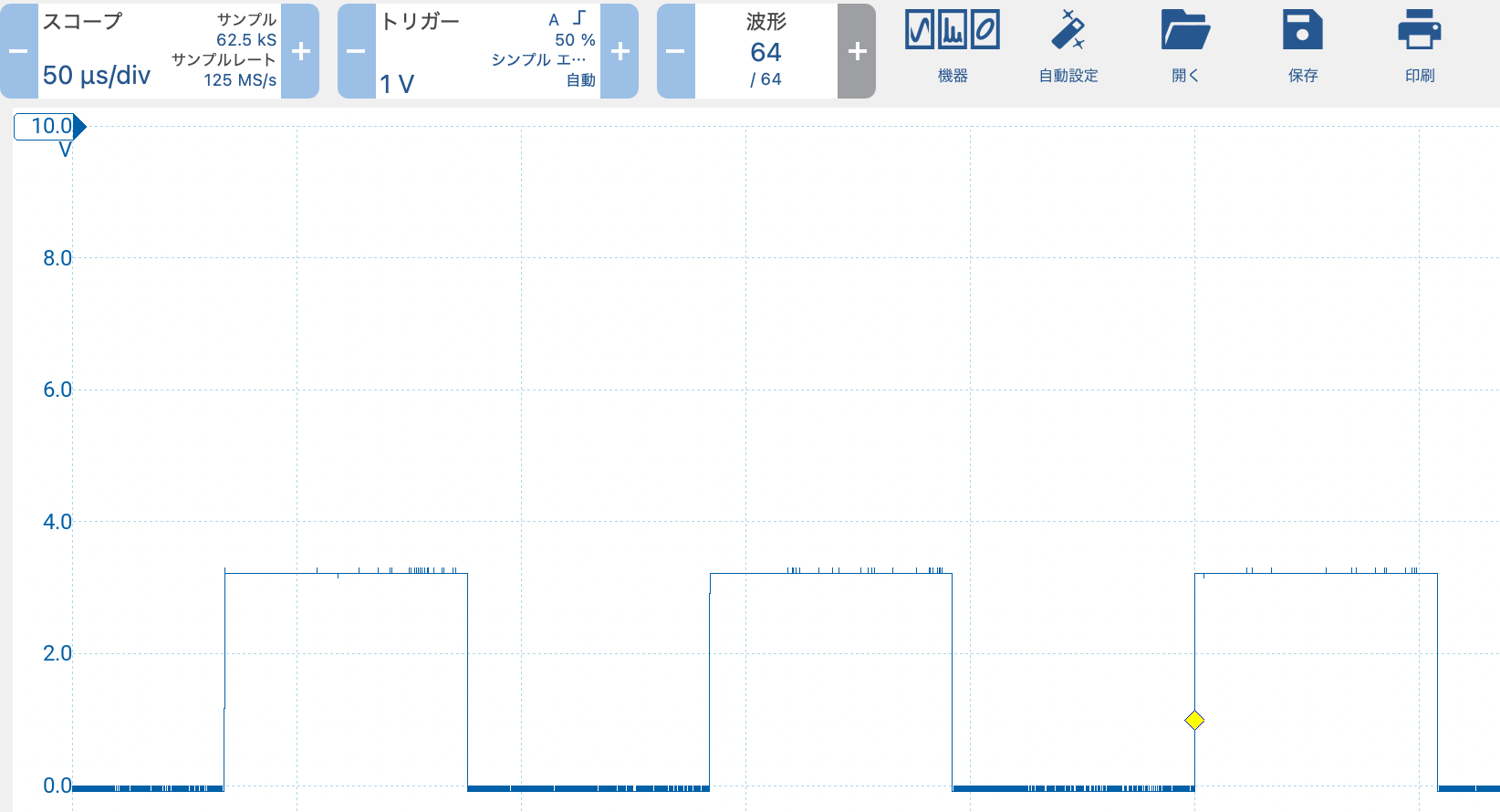
実はスレッドの起動と終了待ちには結構時間かかってそれだけで50μs近くかかるから、時間待ちに数μs以下を指定しても無味
これは1μs時間待ちのケース
そしてこれはスレッド起動をコメントアウトしたもの
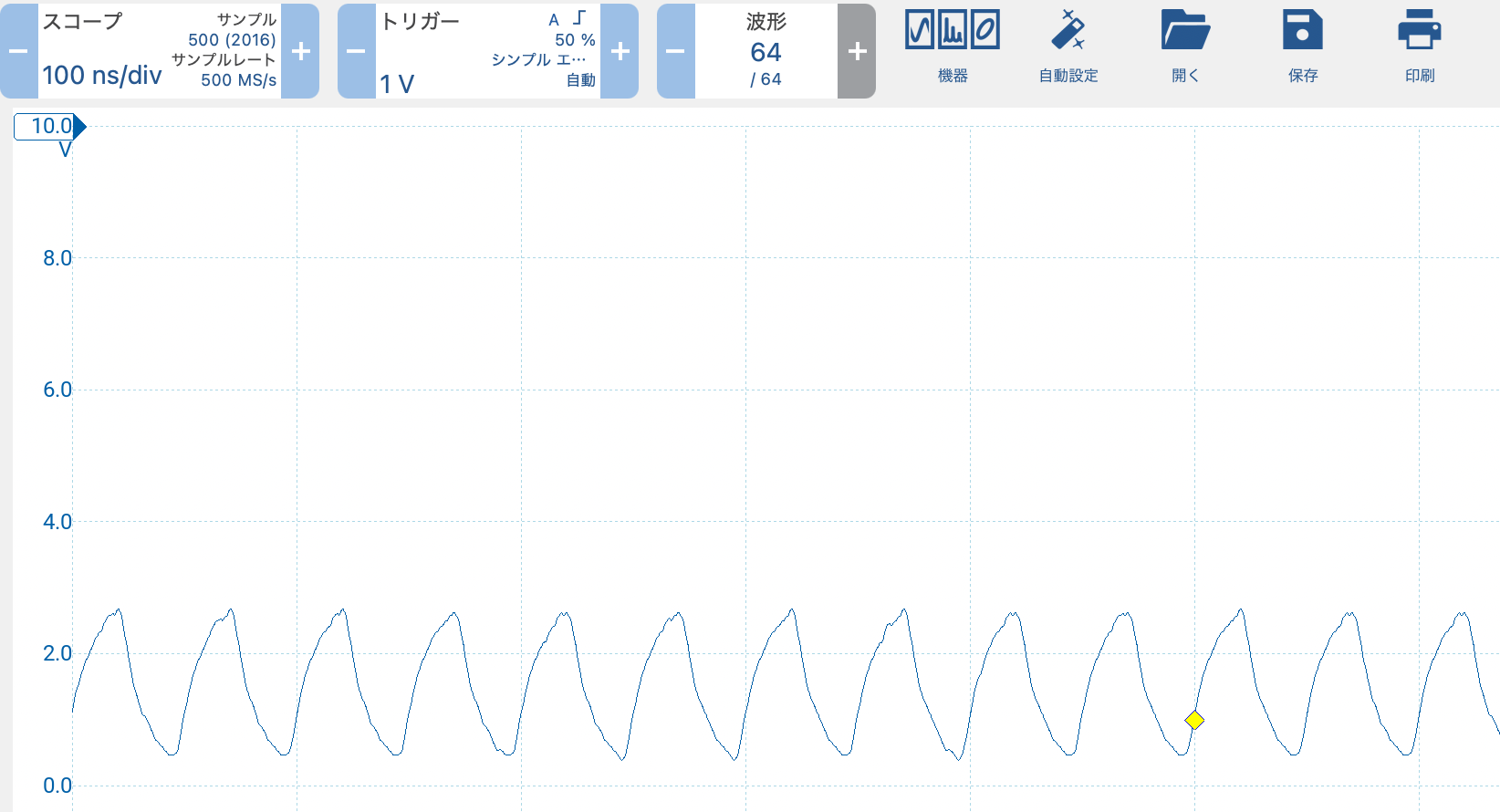
およそ50nsぐらいのパルスになっています、オシロのサンプリング周波数が40MHzぐらいなので、帯域が追いついてないですが
これでもラズピコのgpio制御に比較すると遅いので、組み込み系にはラズピコの方が向いているということなんだろうと思う
admin
音声認識、LLMへのリクエストとレスポンス、text2speechを一連の流れで実行できるようにしてみた
最初はMacでやったけれども、数箇所手直しするだけでラズパイ5でもちゃんと動作、正常系だけなのでユーザエクスペリエンス的にはまだまだ改善必要ですが、
三本のコードのマージはPerplexityで実行させてます、GeminiにPythonからアクセスするためにAPIキーが必要になりますが、以下のリンクから今は無償で取得できます、APIキーはシステム環境変数に保存、他人の資産だからそれはオープンにはできない
https://aistudio.google.com/apikey
<全体のコード>
import vosk
import pyaudio
import json
import numpy as np
import sounddevice as sd
import queue
import threading
import time
import os
from dotenv import load_dotenv
import google.generativeai as genai
import subprocess
class VoskSpeechRecognizer:
def __init__(self, model_path='./vrecog/vosk-model-ja-0.22'):
# モデルの初期化
vosk.SetLogLevel(-1)
self.model = vosk.Model(model_path)
self.recognizer = vosk.KaldiRecognizer(self.model, 16000)
# キュー設定
self.audio_queue = queue.Queue()
self.stop_event = threading.Event()
# マイク設定
self.sample_rate = 16000
self.channels = 1
# スレッド準備
self.recording_thread = threading.Thread(target=self._record_audio)
self.recognition_thread = threading.Thread(target=self._recognize_audio)
def _record_audio(self):
"""
連続的な音声録音スレッド
"""
with sd.InputStream(
samplerate=self.sample_rate,
channels=self.channels,
dtype='int16',
callback=self._audio_callback
):
while not self.stop_event.is_set():
sd.sleep(100)
def _audio_callback(self, indata, frames, time, status):
"""
音声入力のコールバック関数
"""
if status:
print(status)
self.audio_queue.put(indata.copy())
def _recognize_audio(self):
"""
連続的な音声認識スレッド
"""
while not self.stop_event.is_set():
try:
audio_chunk = self.audio_queue.get(timeout=0.5)
if self.recognizer.AcceptWaveform(audio_chunk.tobytes()):
result = json.loads(self.recognizer.Result())
text = result.get('text', '').strip()
if text:
print(f"認識結果: {text}")
response_text = query_gemini(text) # Gemini APIに問い合わせる
jtalk(response_text) # 結果を音声合成して再生する
except queue.Empty:
continue
def start_recognition(self):
"""
音声認識の開始
"""
self.stop_event.clear()
self.recording_thread.start()
self.recognition_thread.start()
def stop_recognition(self):
"""
音声認識の停止
"""
self.stop_event.set()
self.recording_thread.join()
self.recognition_thread.join()
def query_gemini(prompt):
"""
Gemini APIに問い合わせて応答を取得する関数。
"""
try:
response = model.generate_content(prompt)
print(f"Gemini応答: {response.text}")
return response.text.strip()
except Exception as e:
print(f"Gemini APIエラー: {e}")
return "エラーが発生しました。もう一度試してください。"
def jtalk(text):
"""
Open JTalkでテキストを音声合成し再生する関数。
"""
open_jtalk = ['/usr/bin/open_jtalk']
mech = ['-x', '/var/lib/mecab/dic/open-jtalk/naist-jdic']
htsvoice = ['-m', '/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice']
speed = ['-r', '1.0']
outwav = ['-ow', 'out.wav']
cmd = open_jtalk + mech + htsvoice + speed + outwav
try:
proc = subprocess.Popen(cmd, stdin=subprocess.PIPE)
proc.stdin.write(text.encode('utf-8'))
proc.stdin.close()
proc.wait()
# 音声ファイルを再生する場合
subprocess.call(['aplay', 'out.wav'])
except Exception as e:
print(f"音声合成エラー: {e}")
def main():
# 環境変数からGoogle APIキーを読み込む
load_dotenv()
GOOGLE_API_KEY = os.getenv('GOOGLE_API_KEY')
if not GOOGLE_API_KEY:
print("Google APIキーが設定されていません。")
return
# Google Gemini APIの設定
genai.configure(api_key=GOOGLE_API_KEY, transport="rest")
global model # グローバル変数としてモデルを定義(query_geminiで使用)
model = genai.GenerativeModel("gemini-1.5-flash")
recognizer = VoskSpeechRecognizer()
try:
print("音声認識を開始します。Ctrl+Cで終了できます。")
recognizer.start_recognition()
# 無限ループを防ぐ(Ctrl+Cで停止可能)
while True:
time.sleep(1)
except KeyboardInterrupt:
print("\n音声認識を終了します...")
finally:
recognizer.stop_recognition()
if __name__ == "__main__":
main()<動作例>

jtalkは返答の最初のブロックしか読み上げないようだけれども、長いレスポンスを全部読み上げられてもというところだから、最初だけで十分かもしれない
Geminiはマルチモーダルなので、音声認識や合成もクラウドでできそうですが、そこまでクラウドにアップロードは躊躇われるので、端末側で処理するのが妥当じゃないかと今は考えています
admin
カメラはラズパイ標準を使ってみる、
https://www.switch-science.com/products/9933?_pos=5&_sid=3c0939413&_ss=r
オートフォーカスで、ラズパイ専用は特に設定も不要で動く
カメラの見え方は、
$ rpicam-hello --list-cameras
Available cameras
-----------------
0 : imx708 [4608x2592 10-bit RGGB] (/base/axi/pcie@120000/rp1/i2c@88000/imx708@1a)
Modes: 'SRGGB10_CSI2P' : 1536x864 [120.13 fps - (768, 432)/3072x1728 crop]
2304x1296 [56.03 fps - (0, 0)/4608x2592 crop]
4608x2592 [14.35 fps - (0, 0)/4608x2592 crop]物の梱包状態、

FPCは表裏(つまりコネクタの片側にしか接点はない)があるので、間違えないように、写真を見ればわかりますが

コマンド系にはlibcameraとrpicamがありますが、どちらでも動きますが今後はrpicamが標準になっていくらしいのでこちらを使うべき、以下はjpegで取り込む例です
$ libcamera-jpeg -o test.jpg -t 2000 --width 800 --height 600
or
$ rpicam-jpeg -o test.jpg -t 2000 --width 800 --height 600なぜかVNC経由ではフレームレートが1fps以下の極遅モードになりますが、対策方法はヘッドレス(モニターレス)で使われるダミーのHDMIをつなぐのが一番スマートかもしれない、設定は上手くいかなかった、まあデスクトップは最終的に使わないから
表示だけが遅くなるのであって、録画した動画をMacに転送すれば普通に30fpsとかで再生できる、つまりちゃんと録画はされているからラズパイ- VNC転送時の問題です
admin
ラズパイ5ならなんとか処理できそうな、クラウドを使わない、つまりセキュアーな音声認識ソフトでvoskが有力そうだから動かしてみた
元々M1 Macで動かしてみて、small(およそ50MB)と標準の辞書(およそ1.6GB)では明らかに性能差があるから、ラズパイ5でも標準辞書で動かしてみた、懸念はリーズナブルな応答速度で動くかどうか
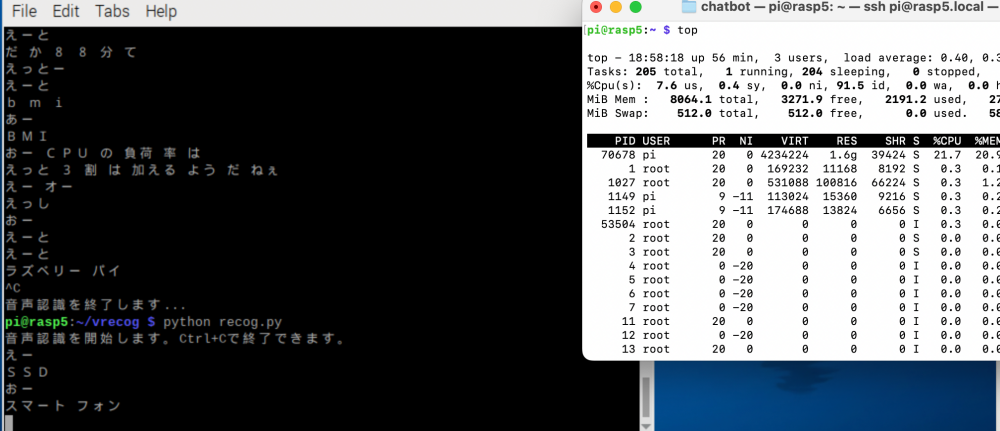
<結果>
まともに動く、cpu負荷率は30%超えるてファンはずっと回るけど使えます
<動作確認コード>
Perplexityで生成したもの、
import vosk
import pyaudio
import json
import numpy as np
import sounddevice as sd
import queue
import threading
import time
class VoskSpeechRecognizer:
def __init__(self, model_path='./vosk-model-ja-0.22'):
# モデルの初期化
vosk.SetLogLevel(-1)
self.model = vosk.Model(model_path)
self.recognizer = vosk.KaldiRecognizer(self.model, 16000)
# キュー設定
self.audio_queue = queue.Queue()
self.stop_event = threading.Event()
# マイク設定
self.sample_rate = 16000
self.channels = 1
# スレッド準備
self.recording_thread = threading.Thread(target=self._record_audio)
self.recognition_thread = threading.Thread(target=self._recognize_audio)
def _record_audio(self):
"""
連続的な音声録音スレッド
"""
with sd.InputStream(
samplerate=self.sample_rate,
channels=self.channels,
dtype='int16',
callback=self._audio_callback
):
while not self.stop_event.is_set():
sd.sleep(100)
def _audio_callback(self, indata, frames, time, status):
"""
音声入力のコールバック関数
"""
if status:
print(status)
self.audio_queue.put(indata.copy())
def _recognize_audio(self):
"""
連続的な音声認識スレッド
"""
while not self.stop_event.is_set():
try:
audio_chunk = self.audio_queue.get(timeout=0.5)
if self.recognizer.AcceptWaveform(audio_chunk.tobytes()):
result = json.loads(self.recognizer.Result())
text = result.get('text', '').strip()
if text:
print(f"{text}")
except queue.Empty:
continue
def start_recognition(self):
"""
音声認識の開始
"""
self.stop_event.clear()
self.recording_thread.start()
self.recognition_thread.start()
def stop_recognition(self):
"""
音声認識の停止
"""
self.stop_event.set()
self.recording_thread.join()
self.recognition_thread.join()
def main():
recognizer = VoskSpeechRecognizer()
try:
print("音声認識を開始します。Ctrl+Cで終了できます。")
recognizer.start_recognition()
# 無限ループを防ぐ
while True:
time.sleep(1)
except KeyboardInterrupt:
print("\n音声認識を終了します...")
finally:
recognizer.stop_recognition()
if __name__ == "__main__":
main()音声辞書と文章解析用の辞書合わせて1.6Gはメモリを消費するから、ラズパイ5のメモリが4GBでは他の機能追加していくと足りなくなるだろう、使い方次第ではsmall辞書(約50MB)でも良いかもしれないけども
admin
まず、間に合わせ使ったsdカードがメチャクチャ遅い、ドラレコから抜いてきたからほぼ寿命終わりらしい
かなり昔のusbメモリにインストして立ち上げた方がはるかに高速、なので追加でSDカード(UHS-1規格)購入してインストすると体感かなりサクサク
shutdown ~ reboot(ログオン完了)時間は、
Shutdown ~ reboot時間
どちらもヘッドレス、
古いmicro SD : 1:40 min/ 2:20 min(媒体終わってるよね)
Stick USB : 1:10 min
SDカード(UHS-1):40 sec(デスクトップモードなのに)という結果、ついでにsdカードのベンチマークは、
UHS-1カードのPiBenchmarks結果
$ sudo curl https://raw.githubusercontent.com/TheRemote/PiBenchmarks/master/Storage.sh | sudo bash
Category Test Result
HDParm Disk Read 90.82 MB/sec
HDParm Cached Disk Read 90.94 MB/sec
DD Disk Write 32.5 MB/s
FIO 4k random read 6317 IOPS (25268 KB/s)
FIO 4k random write 845 IOPS (3382 KB/s)
IOZone 4k read 29989 KB/s
IOZone 4k write 3288 KB/s
IOZone 4k random read 30032 KB/s
IOZone 4k random write 3268 KB/s
Score: 2530 ラズパイ5ではおそらく平均的な値だろう
2. Pythonのインスト
ラズパイではpyenvを使うことが推奨というかほぼマストです
https://zenn.dev/technicarium/articles/00b32d390e82ec
がわかりやすかったのでこのサイトとPerplexityでPyenvと現状安定版の最終3.13.1をインスト、必要なライブラリは都度
3. text2speechでスピーカ機能も確認
音声の入出力にUSB接続のマイクとスピーカーを使いますが、その機能確認含めて、ロワーケースはssd用HAT(見た目ロワ側なのでHATじゃなくてHAB、そのそも上側にはGPIOコントロールのカスタムボードが追加されるし)に置き換えてます

フリーのopen_jtalkのインストと動作確認
open-jtalkインスト
$ sudo apt-get update
$ sudo apt-get install -y open-jtalk open-jtalk-mecab-naist-jdic htsengine libhtsengine-dev hts-voice-nitech-jp-atr503-m001
女性の声のインスト
$ wget https://sourceforge.net/projects/mmdagent/files/MMDAgent_Example/MMDAgent_Example-1.7/MMDAgent_Example-1.7.zip
$ unzip MMDAgent_Example-1.7.zip
$ sudo cp -r ./MMDAgent_Example-1.7/Voice/* /usr/share/hts-voice/合成音声(text2speech)のサンプルコード(Perplexityで作成)
#
# pactl set-sink-volume @DEFAULT_SINK@ +10% 音量アップ
#
import subprocess
import os
from datetime import datetime
def jtalk(text):
open_jtalk = ['/usr/bin/open_jtalk']
mech = ['-x', '/var/lib/mecab/dic/open-jtalk/naist-jdic']
htsvoice = ['-m', '/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice']
speed = ['-r', '1.0']
outwav = ['-ow', 'out.wav']
cmd = open_jtalk + mech + htsvoice + speed + outwav
try:
proc = subprocess.Popen(cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = proc.communicate(input=text.encode('utf-8'))
if proc.returncode != 0:
print(f"Error in open_jtalk: {stderr.decode('utf-8')}")
return
if not os.path.exists('out.wav'):
print("Error: out.wav was not generated.")
return
# Raspberry Pi での音声再生
subprocess.call(['aplay', 'out.wav'])
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == '__main__':
current_time = datetime.now().strftime("%H時%M分")
text = f"現在の時刻は{current_time}です。"
jtalk(text)
4. マイク機能の確認
$ arecord -l
**** List of CAPTURE Hardware Devices ****
card 2: SF558 [SF-558], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0のように見えているので、Linuxの基本コマンドで確認
// record
$ arecord -d 5 -r 12000 out.wav
// play
$ aplay out.wav後ペリフェラルではカメラ必要だけど、それはリサーチの後だな、それにステッピングモータとか駆動させるとACアダプタ5Aで足りるのかな?
admin
ラズパイの現行ハイエンド(8GB品)を購入、今までラズパイ1、zero、picoしか購入履歴ないから史上最高性能、ヒートシンクつけたら見ることないから取り付け前の写真

最終的にはssdで高速化と高信頼性化しますが、とりあえずsdカードでインスト(ほぼ動作確認)してみた
osはssdへの書き込み考慮して、必要ないけどデスクトップバージョンをインスト、sshは書き込み時点のオプション選択でオンにしておかないと手も足も出ないから忘れずに、同時にWi-Fiの設定もしておきます、こちらは最悪有線LAN使えばいいけども
ラズパイの基板保護(特に裏面のチップ部品)のために拾ってきたstlファイルでロワーカバー造形、sdカードとの干渉部分は追加で加工しないと後で泣く(sdカード持ち上げ方向の力ではんだ剥離します

sdカード差込部

デスクトップ版のosインストしても、モニターもキーボードも持っていないからvncでデスクトップ画面をmacから操作します
https://qiita.com/ktamido/items/82ed2f5bd324d4721096
x11を有効化してmac標準のvncではつながらなかったからvnc viewerをインスト、設定だろうけどスクショ撮れなかったからカメラで撮影の画面
admin